Investigating and Simplifying Masking-based Saliency Methods for Model Interpretability
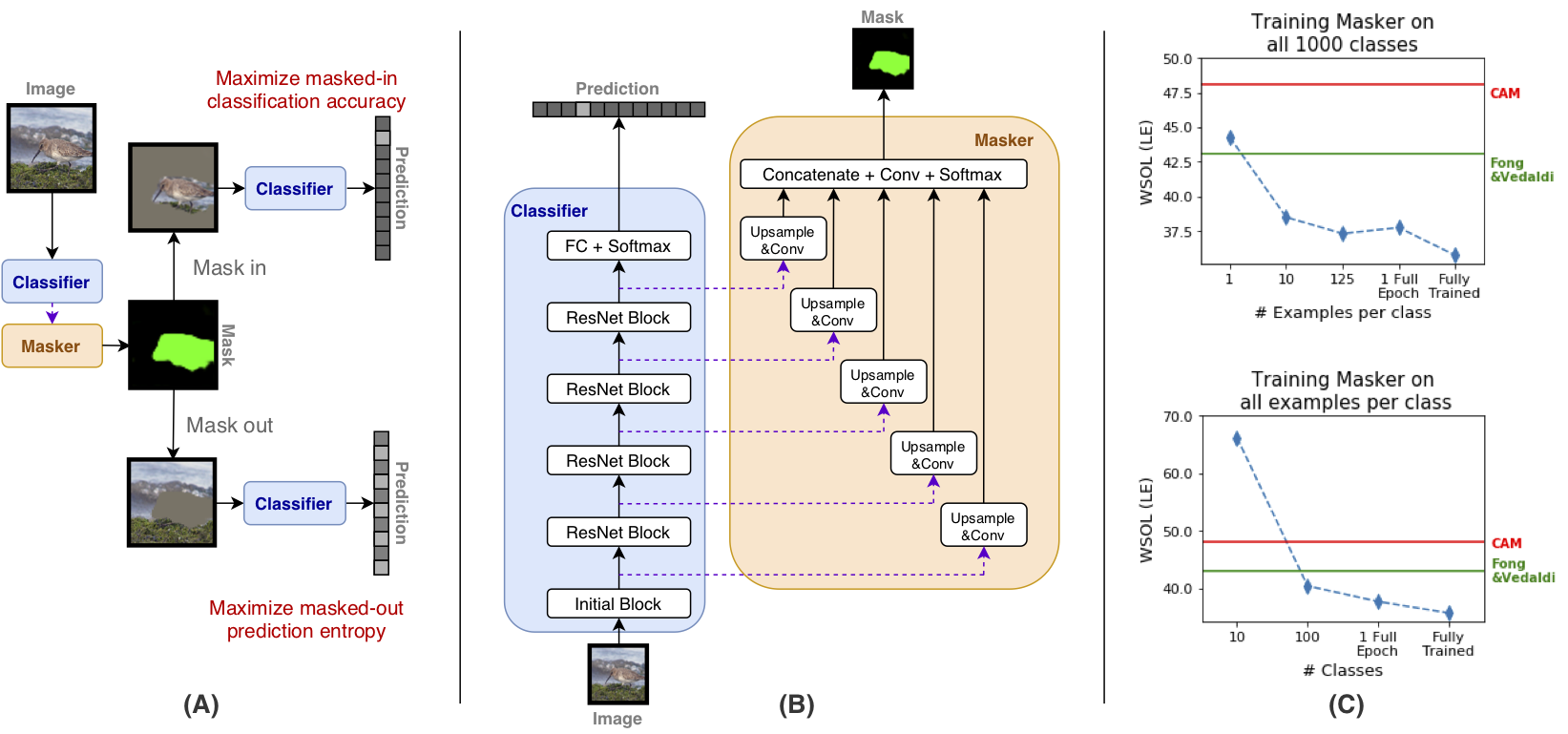
Saliency maps that identify the most informative regions of an image for a classifier are valuable for model interpretability. A common approach to creating saliency maps involves generating input masks that mask out portions of an image to maximally deteriorate classification performance, or mask in an image to preserve classification performance. Many variants of this approach have been proposed in the literature, such as counterfactual generation and optimizing over a Gumbel-Softmax distribution. Using a general formulation of masking-based saliency methods, we conduct an extensive evaluation study of a number of recently proposed variants to understand which elements of these methods meaningfully improve performance. Surprisingly, we find that a well-tuned, relatively simple formulation of a masking-based saliency model outperforms many more complex approaches. We find that the most important ingredients for high quality saliency map generation are (1) using both masked-in and masked-out objectives and (2) training the classifier alongside the masking model. Strikingly, we show that a masking model can be trained with as few as 10 examples per class and still generate saliency maps with only a 0.7-point increase in localization error.
PDF Abstract

 ImageNet
ImageNet
