Investigating Fairness Disparities in Peer Review: A Language Model Enhanced Approach
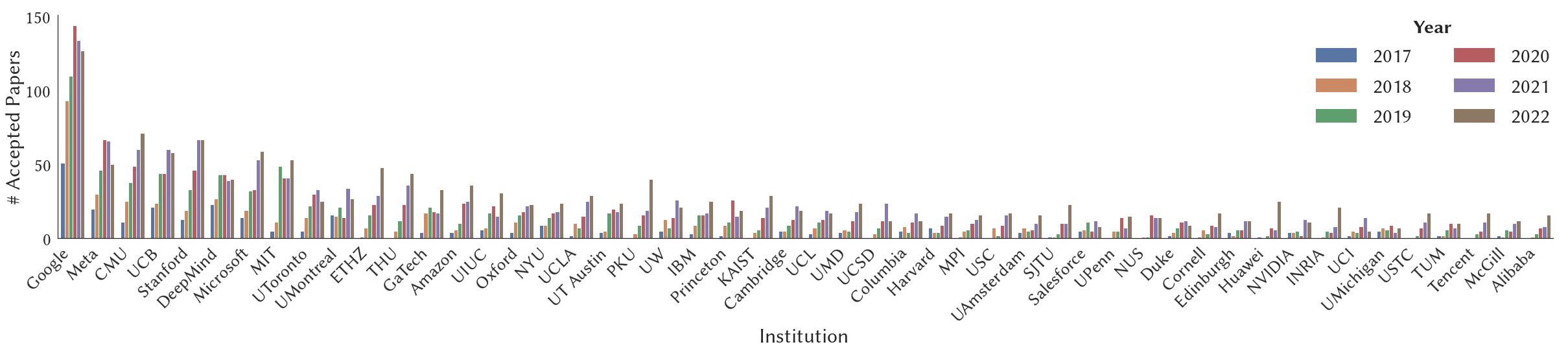
Double-blind peer review mechanism has become the skeleton of academic research across multiple disciplines including computer science, yet several studies have questioned the quality of peer reviews and raised concerns on potential biases in the process. In this paper, we conduct a thorough and rigorous study on fairness disparities in peer review with the help of large language models (LMs). We collect, assemble, and maintain a comprehensive relational database for the International Conference on Learning Representations (ICLR) conference from 2017 to date by aggregating data from OpenReview, Google Scholar, arXiv, and CSRanking, and extracting high-level features using language models. We postulate and study fairness disparities on multiple protective attributes of interest, including author gender, geography, author, and institutional prestige. We observe that the level of disparity differs and textual features are essential in reducing biases in the predictive modeling. We distill several insights from our analysis on study the peer review process with the help of large LMs. Our database also provides avenues for studying new natural language processing (NLP) methods that facilitate the understanding of the peer review mechanism. We study a concrete example towards automatic machine review systems and provide baseline models for the review generation and scoring tasks such that the database can be used as a benchmark.
PDF AbstractCode
 Spaces
Spaces


Datasets
Introduced in the Paper:
 ICLR Database
ICLR Database
