IR2Vec: LLVM IR based Scalable Program Embeddings
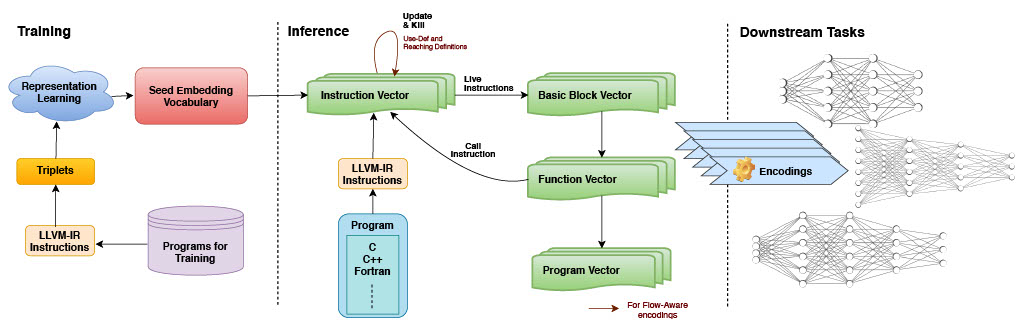
We propose IR2Vec, a Concise and Scalable encoding infrastructure to represent programs as a distributed embedding in continuous space. This distributed embedding is obtained by combining representation learning methods with flow information to capture the syntax as well as the semantics of the input programs. As our infrastructure is based on the Intermediate Representation (IR) of the source code, obtained embeddings are both language and machine independent. The entities of the IR are modeled as relationships, and their representations are learned to form a seed embedding vocabulary. Using this infrastructure, we propose two incremental encodings:Symbolic and Flow-Aware. Symbolic encodings are obtained from the seed embedding vocabulary, and Flow-Aware encodings are obtained by augmenting the Symbolic encodings with the flow information. We show the effectiveness of our methodology on two optimization tasks (Heterogeneous device mapping and Thread coarsening). Our way of representing the programs enables us to use non-sequential models resulting in orders of magnitude of faster training time. Both the encodings generated by IR2Vec outperform the existing methods in both the tasks, even while using simple machine learning models. In particular, our results improve or match the state-of-the-art speedup in 11/14 benchmark-suites in the device mapping task across two platforms and 53/68 benchmarks in the Thread coarsening task across four different platforms. When compared to the other methods, our embeddings are more scalable, is non-data-hungry, and has betterOut-Of-Vocabulary (OOV) characteristics.
PDF Abstract
