Is Information Extraction Solved by ChatGPT? An Analysis of Performance, Evaluation Criteria, Robustness and Errors
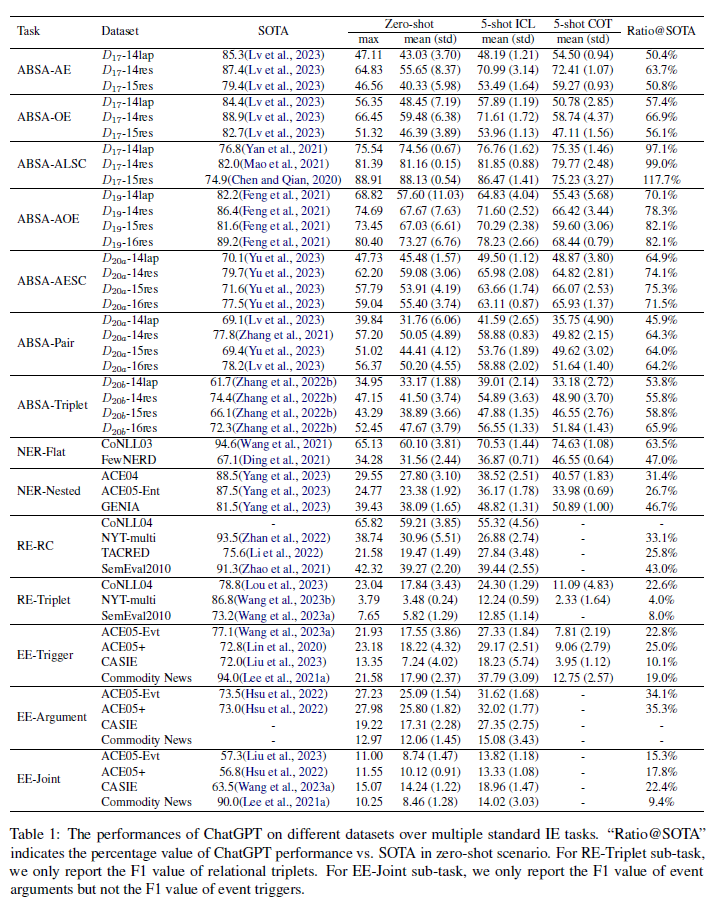
ChatGPT has stimulated the research boom in the field of large language models. In this paper, we assess the capabilities of ChatGPT from four perspectives including Performance, Evaluation Criteria, Robustness and Error Types. Specifically, we first evaluate ChatGPT's performance on 17 datasets with 14 IE sub-tasks under the zero-shot, few-shot and chain-of-thought scenarios, and find a huge performance gap between ChatGPT and SOTA results. Next, we rethink this gap and propose a soft-matching strategy for evaluation to more accurately reflect ChatGPT's performance. Then, we analyze the robustness of ChatGPT on 14 IE sub-tasks, and find that: 1) ChatGPT rarely outputs invalid responses; 2) Irrelevant context and long-tail target types greatly affect ChatGPT's performance; 3) ChatGPT cannot understand well the subject-object relationships in RE task. Finally, we analyze the errors of ChatGPT, and find that "unannotated spans" is the most dominant error type. This raises concerns about the quality of annotated data, and indicates the possibility of annotating data with ChatGPT. The data and code are released at Github site.
PDF Abstract TACRED
TACRED
 Few-NERD
Few-NERD
