Jointly Reparametrized Multi-Layer Adaptation for Efficient and Private Tuning
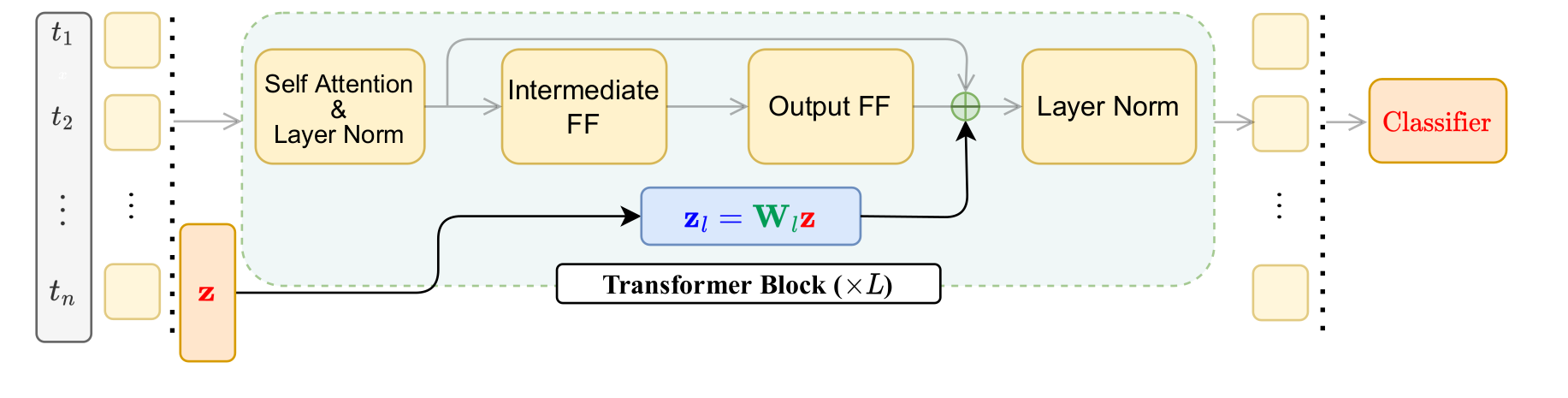
Efficient finetuning of pretrained language transformers is becoming increasingly prevalent for solving natural language processing tasks. While effective, it can still require a large number of tunable parameters. This can be a drawback for low-resource applications and training with differential-privacy constraints, where excessive noise may be introduced during finetuning. To this end, we propose a novel language transformer finetuning strategy that introduces task-specific parameters in multiple transformer layers. These parameters are derived from fixed random projections of a single trainable vector, enabling finetuning with significantly fewer parameters while maintaining performance. We achieve within 5% of full finetuning performance on GLUE tasks with as few as 4,100 parameters per task, outperforming other parameter-efficient finetuning approaches that use a similar number of per-task parameters. Besides, the random projections can be precomputed at inference, avoiding additional computational latency. All these make our method particularly appealing for low-resource applications. Finally, our method achieves the best or comparable utility compared to several recent finetuning methods when training with the same privacy constraints, underscoring its effectiveness and potential real-world impact.
PDF Abstract
 GLUE
GLUE
 QNLI
QNLI
