Pruning Small Pre-Trained Weights Irreversibly and Monotonically Impairs "Difficult" Downstream Tasks in LLMs
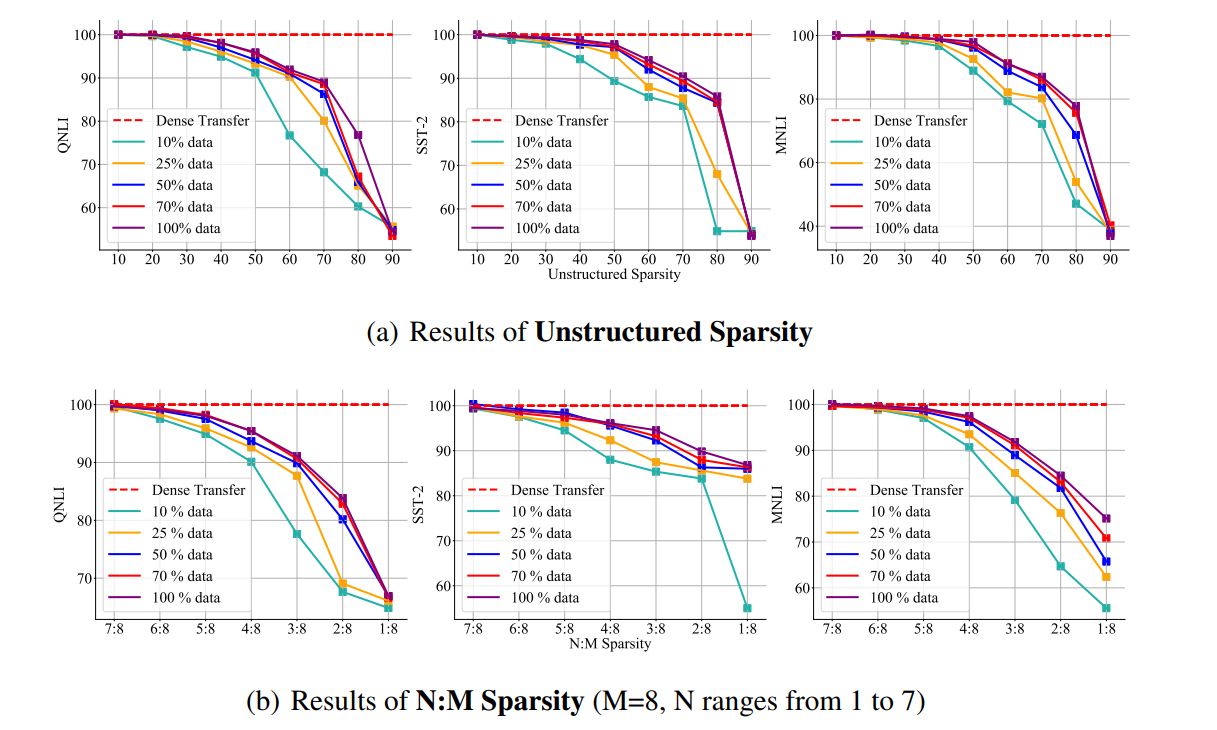
We present Junk DNA Hypothesis by adopting a novel task-centric angle for the pre-trained weights of large language models (LLMs). It has been believed that weights in LLMs contain significant redundancy, leading to the conception that a considerable chunk of the parameters can be removed by pruning without compromising performance. Contrary to this belief, this paper presents a counter-argument: small-magnitude weights of pre-trained model weights encode vital knowledge essential for tackling difficult downstream tasks - manifested as the monotonic relationship between the performance drop of downstream tasks across the difficulty spectrum, as we prune more pre-trained weights by magnitude. Moreover, we reveal that these seemingly inconsequential weights can result in irreparable loss of knowledge and performance degradation in difficult tasks, even when downstream continual training is allowed. Interestingly, our evaluations show that the other popular compression, namely quantization, fails to exhibit similar monotonic effect and does not as convincingly disentangle this task-difficulty information. To study formally, we introduce several quantifiable metrics to gauge the downstream task difficulty: (1) within the same task category, and (2) across different task categories. Our extensive experiments substantiate the Junk DNA Hypothesis across a diverse range of model sizes, tasks, datasets, and even pruning methods. Codes are available at: https://github.com/VITA-Group/Junk_DNA_Hypothesis.git.
PDF Abstract

 GLUE
GLUE
 QNLI
QNLI
 MMLU
MMLU
 TriviaQA
TriviaQA
 HellaSwag
HellaSwag
 PIQA
PIQA
 OpenBookQA
OpenBookQA
