KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
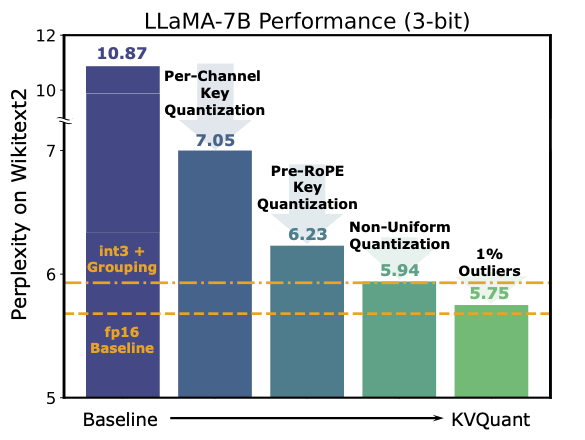
LLMs are seeing growing use for applications such as document analysis and summarization which require large context windows, and with these large context windows KV cache activations surface as the dominant contributor to memory consumption during inference. Quantization is a promising approach for compressing KV cache activations; however, existing solutions fail to represent activations accurately in ultra-low precisions, such as sub-4-bit. In this work, we present KVQuant, which addresses this problem by incorporating novel methods for quantizing cached KV activations, including: (i) Per-Channel Key Quantization, where we adjust the dimension along which we quantize the Key activations to better match the distribution; (ii) Pre-RoPE Key Quantization, where we quantize Key activations before the rotary positional embedding to mitigate its impact on quantization; (iii) Non-Uniform KV Cache Quantization, where we derive per-layer sensitivity-weighted non-uniform datatypes that better represent the distributions; (iv) Per-Vector Dense-and-Sparse Quantization, where we isolate outliers separately for each vector to minimize skews in quantization ranges; and (v) Q-Norm, where we normalize quantization centroids in order to mitigate distribution shift, providing additional benefits for 2-bit quantization. By applying our method to the LLaMA, LLaMA-2, and Mistral models, we achieve $<0.1$ perplexity degradation with 3-bit quantization on both Wikitext-2 and C4, outperforming existing approaches. Our method enables serving the LLaMA-7B model with a context length of up to 1 million on a single A100-80GB GPU and up to 10 million on an 8-GPU system.
PDF Abstract

