Language Model Prior for Low-Resource Neural Machine Translation
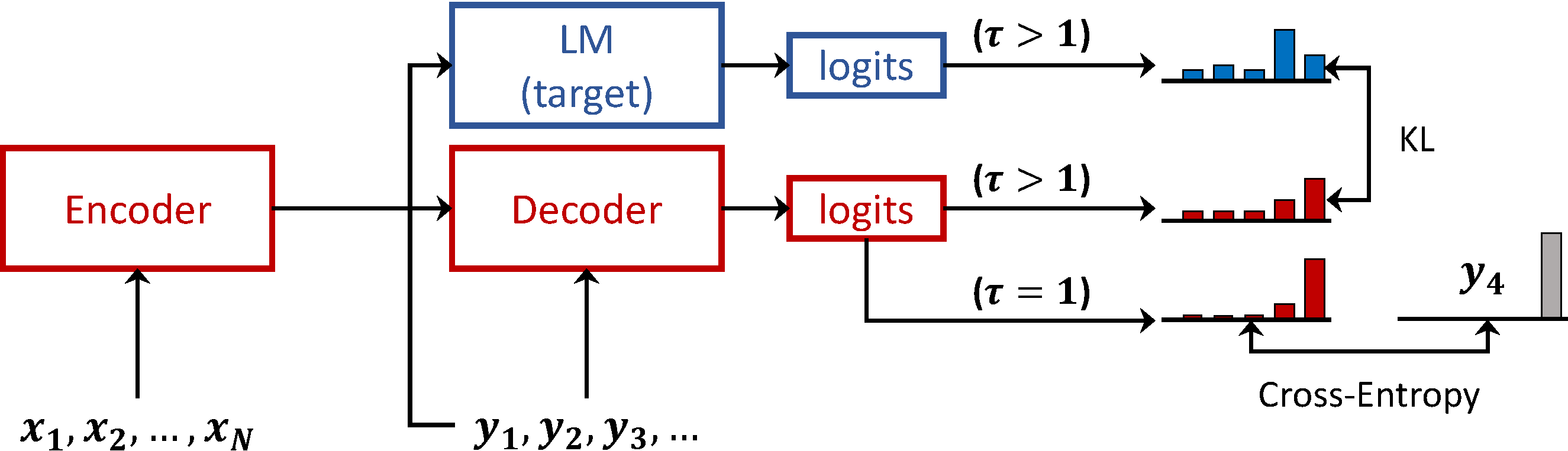
The scarcity of large parallel corpora is an important obstacle for neural machine translation. A common solution is to exploit the knowledge of language models (LM) trained on abundant monolingual data. In this work, we propose a novel approach to incorporate a LM as prior in a neural translation model (TM). Specifically, we add a regularization term, which pushes the output distributions of the TM to be probable under the LM prior, while avoiding wrong predictions when the TM "disagrees" with the LM. This objective relates to knowledge distillation, where the LM can be viewed as teaching the TM about the target language. The proposed approach does not compromise decoding speed, because the LM is used only at training time, unlike previous work that requires it during inference. We present an analysis of the effects that different methods have on the distributions of the TM. Results on two low-resource machine translation datasets show clear improvements even with limited monolingual data.
PDF Abstract EMNLP 2020 PDF EMNLP 2020 Abstract




 WMT 2018
WMT 2018
