Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes
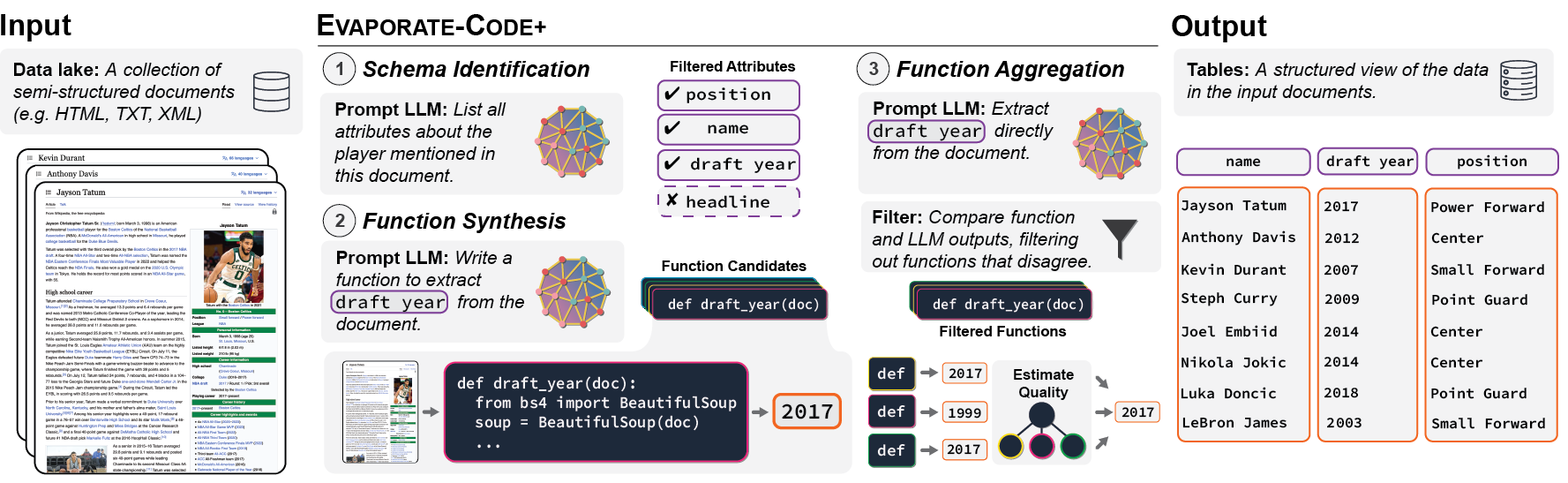
A long standing goal of the data management community is to develop general, automated systems that ingest semi-structured documents and output queryable tables without human effort or domain specific customization. Given the sheer variety of potential documents, state-of-the art systems make simplifying assumptions and use domain specific training. In this work, we ask whether we can maintain generality by using large language models (LLMs). LLMs, which are pretrained on broad data, can perform diverse downstream tasks simply conditioned on natural language task descriptions. We propose and evaluate EVAPORATE, a simple, prototype system powered by LLMs. We identify two fundamentally different strategies for implementing this system: prompt the LLM to directly extract values from documents or prompt the LLM to synthesize code that performs the extraction. Our evaluations show a cost-quality tradeoff between these two approaches. Code synthesis is cheap, but far less accurate than directly processing each document with the LLM. To improve quality while maintaining low cost, we propose an extended code synthesis implementation, EVAPORATE-CODE+, which achieves better quality than direct extraction. Our key insight is to generate many candidate functions and ensemble their extractions using weak supervision. EVAPORATE-CODE+ not only outperforms the state-of-the art systems, but does so using a sublinear pass over the documents with the LLM. This equates to a 110x reduction in the number of tokens the LLM needs to process, averaged across 16 real-world evaluation settings of 10k documents each.
PDF Abstract