LaPA: Latent Prompt Assist Model For Medical Visual Question Answering
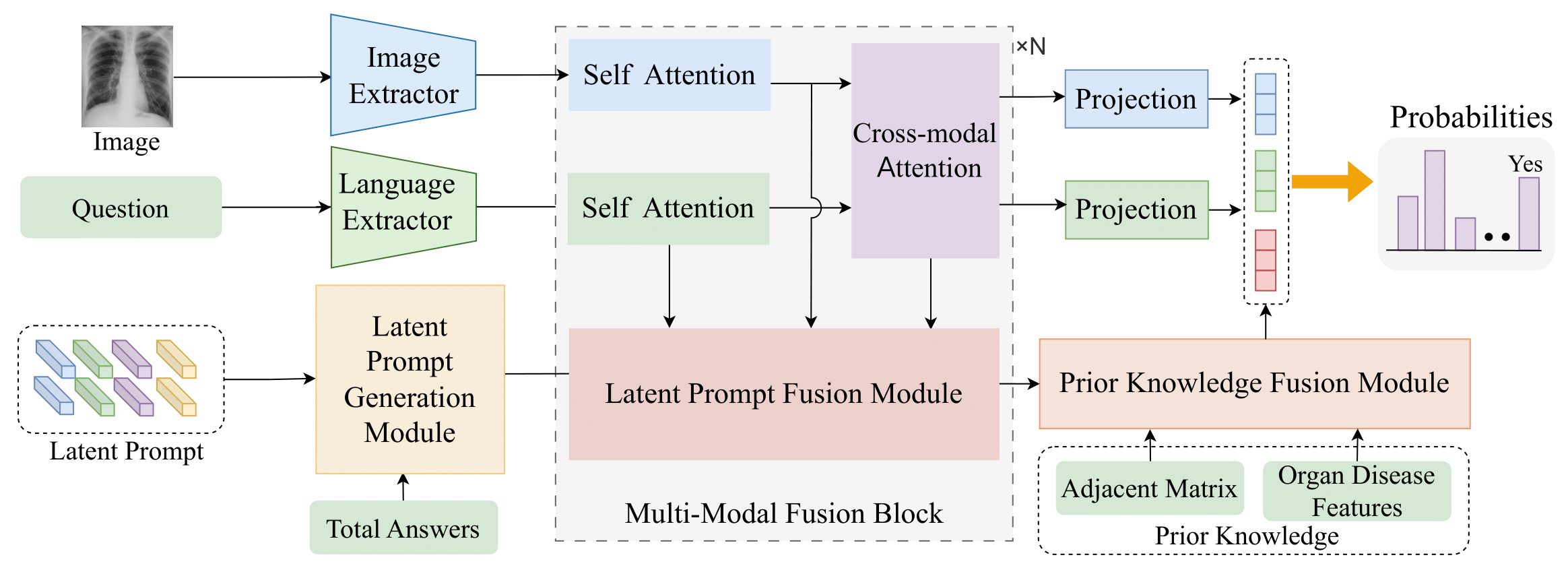
Medical visual question answering (Med-VQA) aims to automate the prediction of correct answers for medical images and questions, thereby assisting physicians in reducing repetitive tasks and alleviating their workload. Existing approaches primarily focus on pre-training models using additional and comprehensive datasets, followed by fine-tuning to enhance performance in downstream tasks. However, there is also significant value in exploring existing models to extract clinically relevant information. In this paper, we propose the Latent Prompt Assist model (LaPA) for medical visual question answering. Firstly, we design a latent prompt generation module to generate the latent prompt with the constraint of the target answer. Subsequently, we propose a multi-modal fusion block with latent prompt fusion module that utilizes the latent prompt to extract clinical-relevant information from uni-modal and multi-modal features. Additionally, we introduce a prior knowledge fusion module to integrate the relationship between diseases and organs with the clinical-relevant information. Finally, we combine the final integrated information with image-language cross-modal information to predict the final answers. Experimental results on three publicly available Med-VQA datasets demonstrate that LaPA outperforms the state-of-the-art model ARL, achieving improvements of 1.83%, 0.63%, and 1.80% on VQA-RAD, SLAKE, and VQA-2019, respectively. The code is publicly available at https://github.com/GaryGuTC/LaPA_model.
PDF Abstract



 VQA-RAD
VQA-RAD
