Large Language Models are Temporal and Causal Reasoners for Video Question Answering
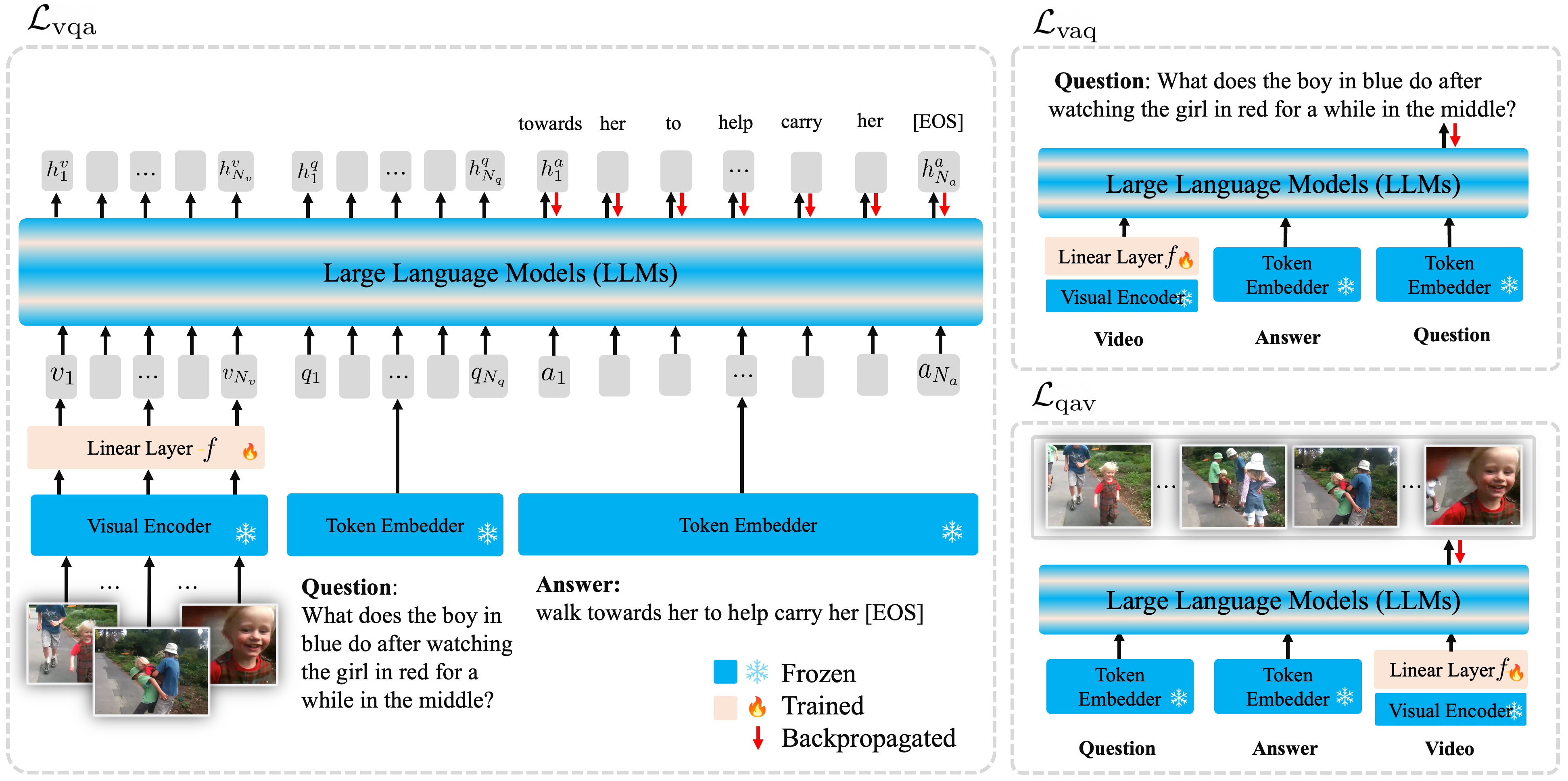
Large Language Models (LLMs) have shown remarkable performances on a wide range of natural language understanding and generation tasks. We observe that the LLMs provide effective priors in exploiting $\textit{linguistic shortcuts}$ for temporal and causal reasoning in Video Question Answering (VideoQA). However, such priors often cause suboptimal results on VideoQA by leading the model to over-rely on questions, $\textit{i.e.}$, $\textit{linguistic bias}$, while ignoring visual content. This is also known as `ungrounded guesses' or `hallucinations'. To address this problem while leveraging LLMs' prior on VideoQA, we propose a novel framework, Flipped-VQA, encouraging the model to predict all the combinations of $\langle$V, Q, A$\rangle$ triplet by flipping the source pair and the target label to understand their complex relationships, $\textit{i.e.}$, predict A, Q, and V given a VQ, VA, and QA pairs, respectively. In this paper, we develop LLaMA-VQA by applying Flipped-VQA to LLaMA, and it outperforms both LLMs-based and non-LLMs-based models on five challenging VideoQA benchmarks. Furthermore, our Flipped-VQA is a general framework that is applicable to various LLMs (OPT and GPT-J) and consistently improves their performances. We empirically demonstrate that Flipped-VQA not only enhances the exploitation of linguistic shortcuts but also mitigates the linguistic bias, which causes incorrect answers over-relying on the question. Code is available at https://github.com/mlvlab/Flipped-VQA.
PDF Abstract



 TVQA
TVQA
 NExT-QA
NExT-QA
 STAR Benchmark
STAR Benchmark
 VLEP
VLEP

