Learning Filterbanks from Raw Speech for Phone Recognition
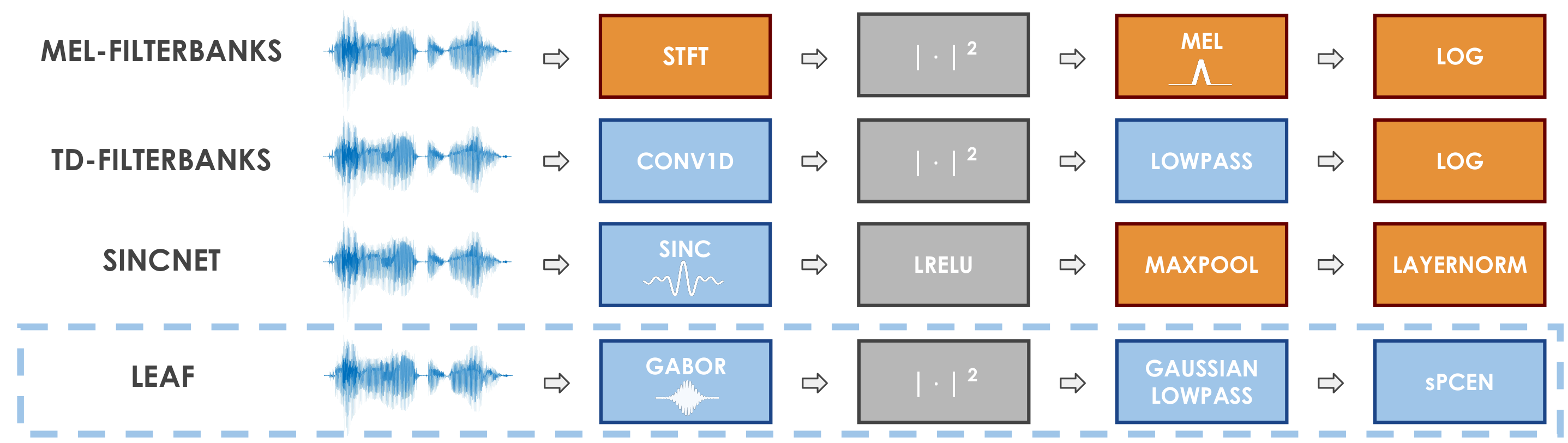
We train a bank of complex filters that operates on the raw waveform and is fed into a convolutional neural network for end-to-end phone recognition. These time-domain filterbanks (TD-filterbanks) are initialized as an approximation of mel-filterbanks, and then fine-tuned jointly with the remaining convolutional architecture. We perform phone recognition experiments on TIMIT and show that for several architectures, models trained on TD-filterbanks consistently outperform their counterparts trained on comparable mel-filterbanks. We get our best performance by learning all front-end steps, from pre-emphasis up to averaging. Finally, we observe that the filters at convergence have an asymmetric impulse response, and that some of them remain almost analytic.
PDF Abstract

