Learning Grounded Vision-Language Representation for Versatile Understanding in Untrimmed Videos
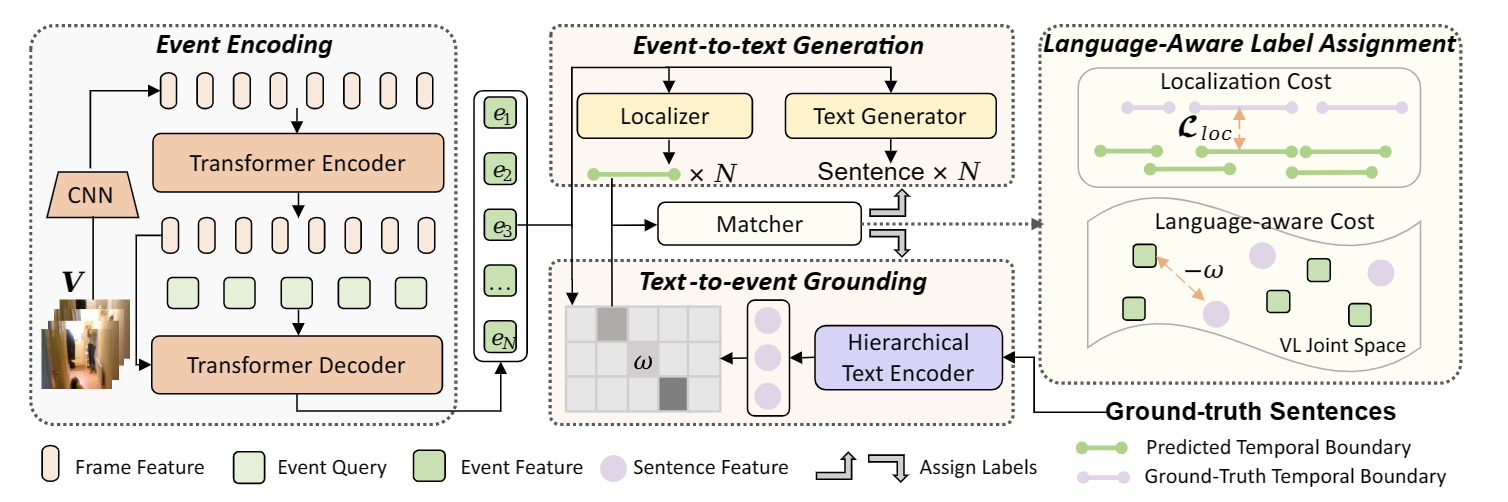
Joint video-language learning has received increasing attention in recent years. However, existing works mainly focus on single or multiple trimmed video clips (events), which makes human-annotated event boundaries necessary during inference. To break away from the ties, we propose a grounded vision-language learning framework for untrimmed videos, which automatically detects informative events and effectively excavates the alignments between multi-sentence descriptions and corresponding event segments. Instead of coarse-level video-language alignments, we present two dual pretext tasks to encourage fine-grained segment-level alignments, i.e., text-to-event grounding (TEG) and event-to-text generation (ETG). TEG learns to adaptively ground the possible event proposals given a set of sentences by estimating the cross-modal distance in a joint semantic space. Meanwhile, ETG aims to reconstruct (generate) the matched texts given event proposals, encouraging the event representation to retain meaningful semantic information. To encourage accurate label assignment between the event set and the text set, we propose a novel semantic-aware cost to mitigate the sub-optimal matching results caused by ambiguous boundary annotations. Our framework is easily extensible to tasks covering visually-grounded language understanding and generation. We achieve state-of-the-art dense video captioning performance on ActivityNet Captions, YouCook2 and YouMakeup, and competitive performance on several other language generation and understanding tasks. Our method also achieved 1st place in both the MTVG and MDVC tasks of the PIC 4th Challenge. Our code is publicly available at https://github.com/zjr2000/GVL.
PDF Abstract


 ActivityNet
ActivityNet
 ActivityNet Captions
ActivityNet Captions
 YouCook2
YouCook2

