Learning to Contextually Aggregate Multi-Source Supervision for Sequence Labeling
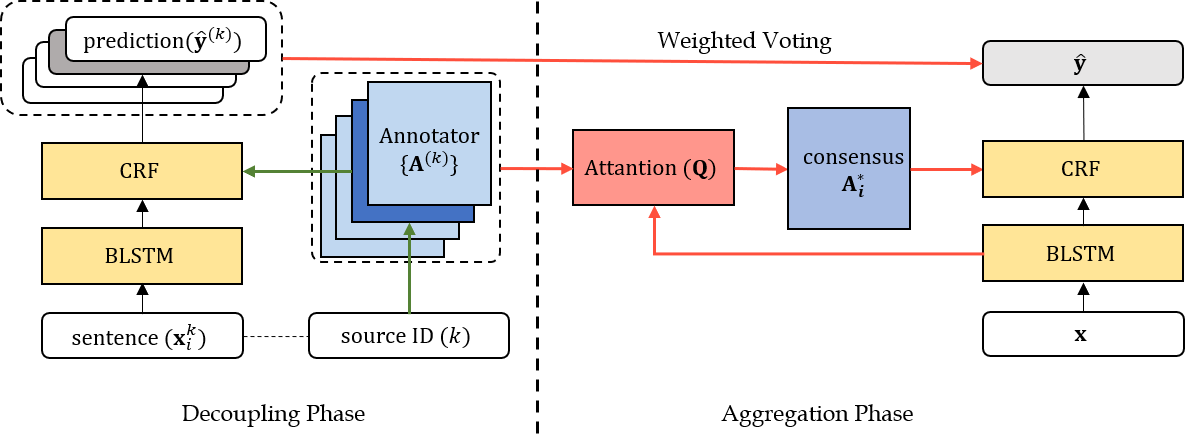
Sequence labeling is a fundamental framework for various natural language processing problems. Its performance is largely influenced by the annotation quality and quantity in supervised learning scenarios, and obtaining ground truth labels is often costly. In many cases, ground truth labels do not exist, but noisy annotations or annotations from different domains are accessible. In this paper, we propose a novel framework Consensus Network (ConNet) that can be trained on annotations from multiple sources (e.g., crowd annotation, cross-domain data...). It learns individual representation for every source and dynamically aggregates source-specific knowledge by a context-aware attention module. Finally, it leads to a model reflecting the agreement (consensus) among multiple sources. We evaluate the proposed framework in two practical settings of multi-source learning: learning with crowd annotations and unsupervised cross-domain model adaptation. Extensive experimental results show that our model achieves significant improvements over existing methods in both settings. We also demonstrate that the method can apply to various tasks and cope with different encoders.
PDF Abstract ACL 2020 PDF ACL 2020 Abstract
 GUM
GUM
