Learning to Split for Automatic Bias Detection
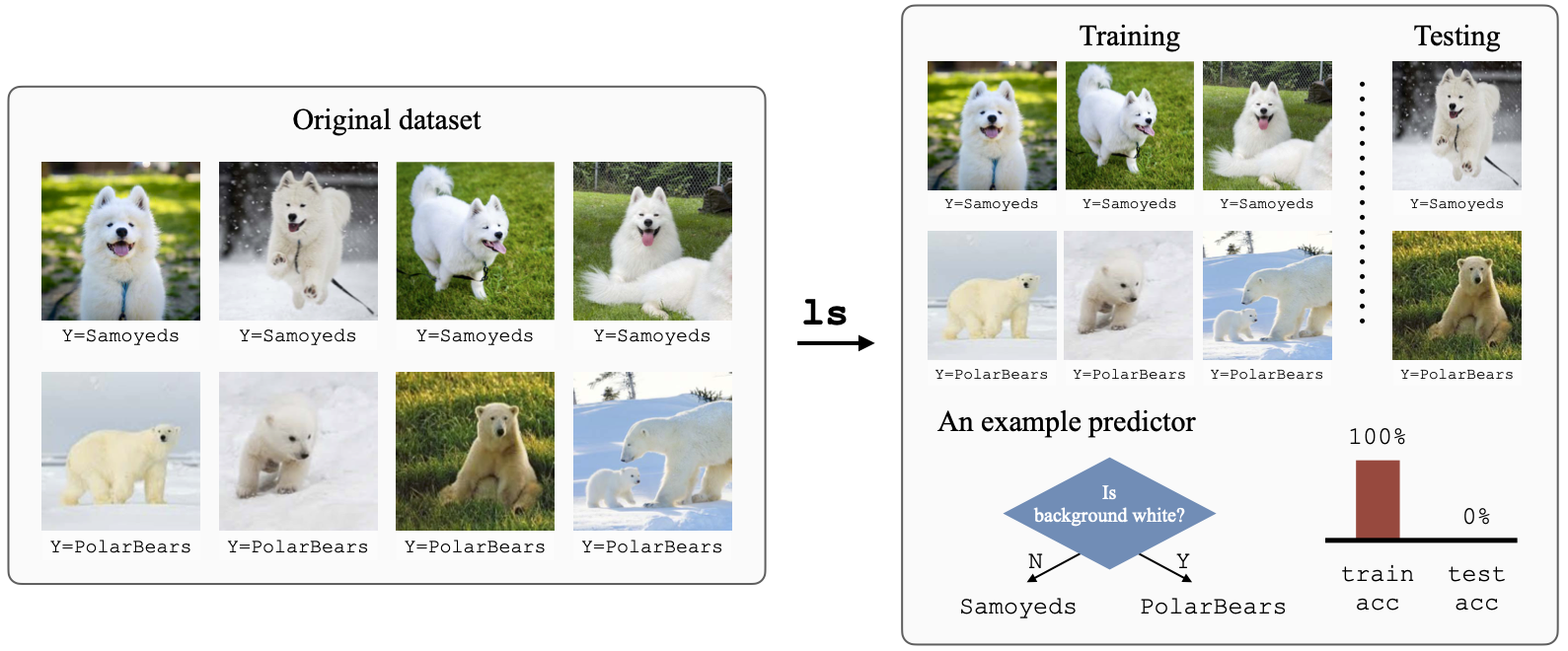
Classifiers are biased when trained on biased datasets. As a remedy, we propose Learning to Split (ls), an algorithm for automatic bias detection. Given a dataset with input-label pairs, ls learns to split this dataset so that predictors trained on the training split cannot generalize to the testing split. This performance gap suggests that the testing split is under-represented in the dataset, which is a signal of potential bias. Identifying non-generalizable splits is challenging since we have no annotations about the bias. In this work, we show that the prediction correctness of each example in the testing split can be used as a source of weak supervision: generalization performance will drop if we move examples that are predicted correctly away from the testing split, leaving only those that are mis-predicted. ls is task-agnostic and can be applied to any supervised learning problem, ranging from natural language understanding and image classification to molecular property prediction. Empirical results show that ls is able to generate astonishingly challenging splits that correlate with human-identified biases. Moreover, we demonstrate that combining robust learning algorithms (such as group DRO) with splits identified by ls enables automatic de-biasing. Compared to previous state-of-the-art, we substantially improve the worst-group performance (23.4% on average) when the source of biases is unknown during training and validation.
PDF Abstract


 CelebA
CelebA
 MultiNLI
MultiNLI
 BAR
BAR
