How Two-Layer Neural Networks Learn, One (Giant) Step at a Time
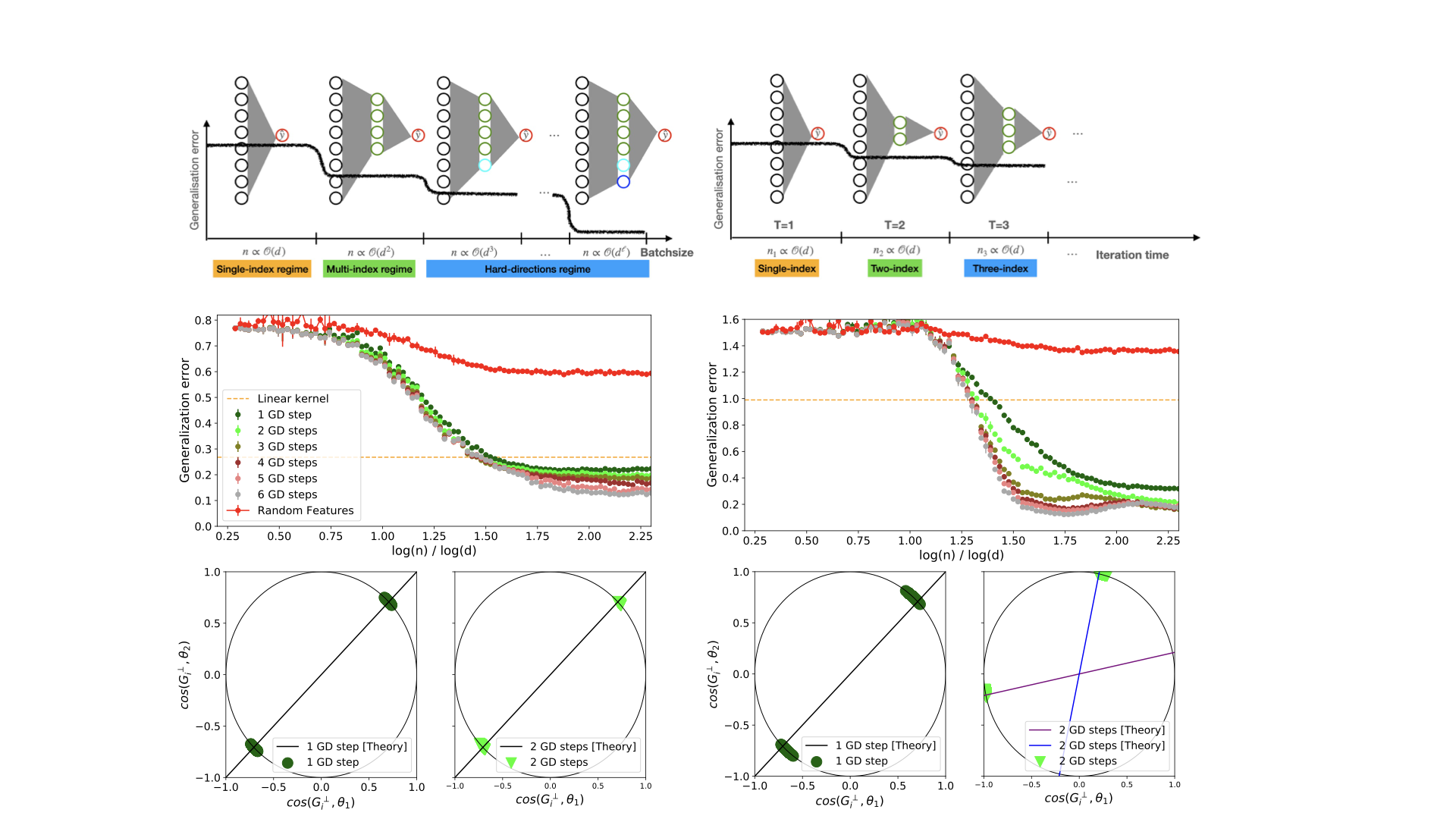
We investigate theoretically how the features of a two-layer neural network adapt to the structure of the target function through a few large batch gradient descent steps, leading to improvement in the approximation capacity with respect to the initialization. We compare the influence of batch size and that of multiple (but finitely many) steps. For a single gradient step, a batch of size $n = \mathcal{O}(d)$ is both necessary and sufficient to align with the target function, although only a single direction can be learned. In contrast, $n = \mathcal{O}(d^2)$ is essential for neurons to specialize to multiple relevant directions of the target with a single gradient step. Even in this case, we show there might exist ``hard'' directions requiring $n = \mathcal{O}(d^\ell)$ samples to be learned, where $\ell$ is known as the leap index of the target. The picture drastically improves over multiple gradient steps: we show that a batch-size of $n = \mathcal{O}(d)$ is indeed enough to learn multiple target directions satisfying a staircase property, where more and more directions can be learned over time. Finally, we discuss how these directions allows to drastically improve the approximation capacity and generalization error over the initialization, illustrating a separation of scale between the random features/lazy regime, and the feature learning regime. Our technical analysis leverages a combination of techniques related to concentration, projection-based conditioning, and Gaussian equivalence which we believe are of independent interest. By pinning down the conditions necessary for specialization and learning, our results highlight the interaction between batch size and number of iterations, and lead to a hierarchical depiction where learning performance exhibits a stairway to accuracy over time and batch size, shedding new light on how neural networks adapt to features of the data.
PDF Abstract