Less is More for Long Document Summary Evaluation by LLMs
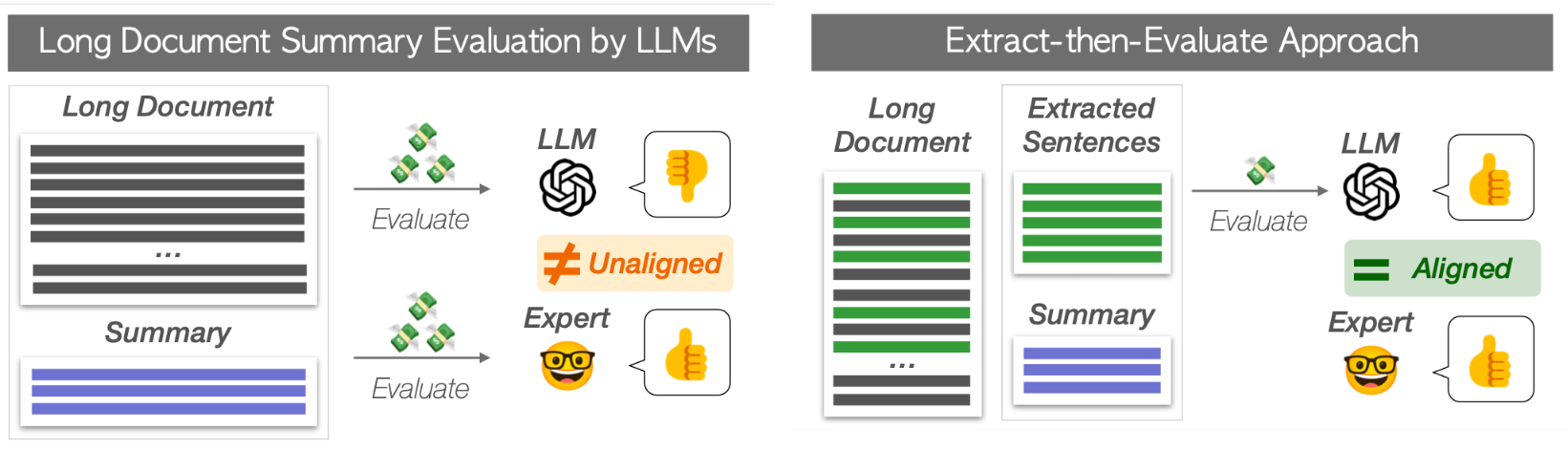
Large Language Models (LLMs) have shown promising performance in summary evaluation tasks, yet they face challenges such as high computational costs and the Lost-in-the-Middle problem where important information in the middle of long documents is often overlooked. To address these issues, this paper introduces a novel approach, Extract-then-Evaluate, which involves extracting key sentences from a long source document and then evaluating the summary by prompting LLMs. The results reveal that the proposed method not only significantly reduces evaluation costs but also exhibits a higher correlation with human evaluations. Furthermore, we provide practical recommendations for optimal document length and sentence extraction methods, contributing to the development of cost-effective yet more accurate methods for LLM-based text generation evaluation.
PDF Abstract

 MultiNLI
MultiNLI
