Leveraging Geometry for Shape Estimation from a Single RGB Image
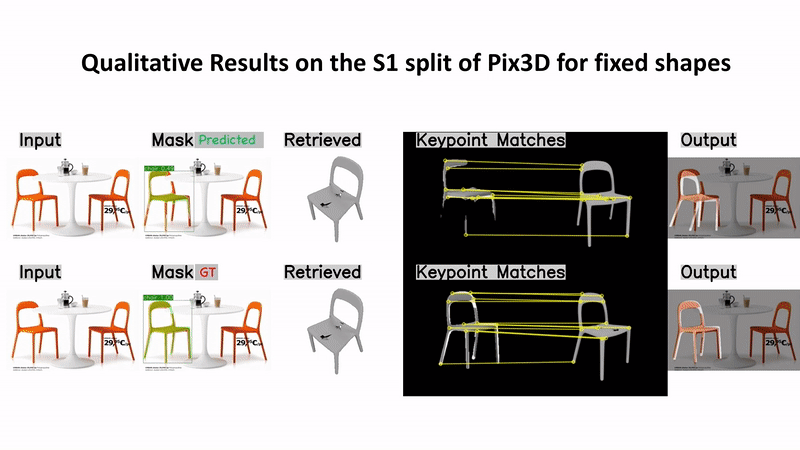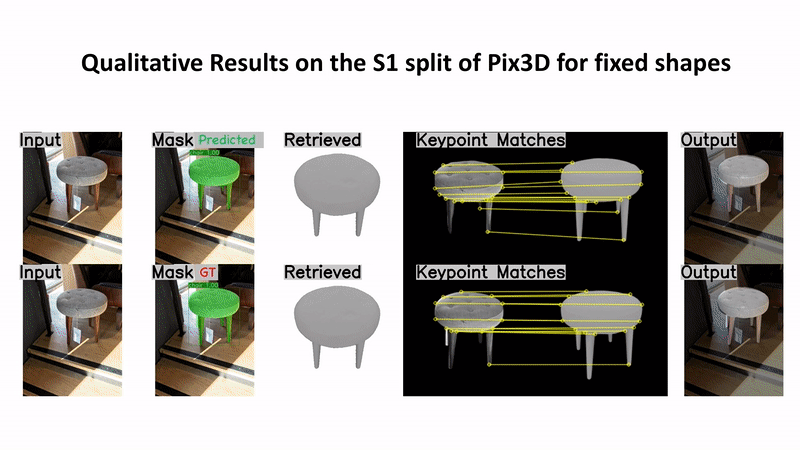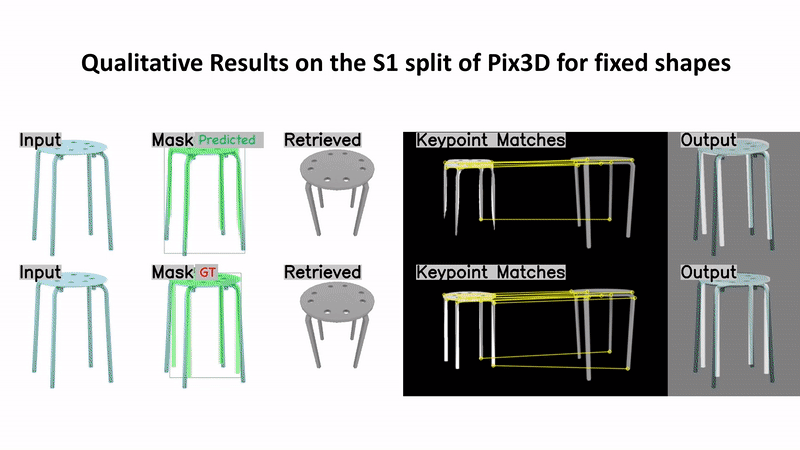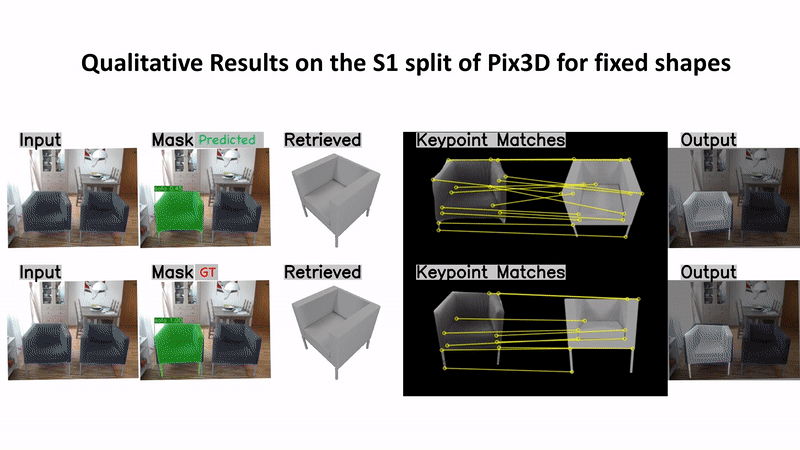
Predicting 3D shapes and poses of static objects from a single RGB image is an important research area in modern computer vision. Its applications range from augmented reality to robotics and digital content creation. Typically this task is performed through direct object shape and pose predictions which is inaccurate. A promising research direction ensures meaningful shape predictions by retrieving CAD models from large scale databases and aligning them to the objects observed in the image. However, existing work does not take the object geometry into account, leading to inaccurate object pose predictions, especially for unseen objects. In this work we demonstrate how cross-domain keypoint matches from an RGB image to a rendered CAD model allow for more precise object pose predictions compared to ones obtained through direct predictions. We further show that keypoint matches can not only be used to estimate the pose of an object, but also to modify the shape of the object itself. This is important as the accuracy that can be achieved with object retrieval alone is inherently limited to the available CAD models. Allowing shape adaptation bridges the gap between the retrieved CAD model and the observed shape. We demonstrate our approach on the challenging Pix3D dataset. The proposed geometric shape prediction improves the AP mesh over the state-of-the-art from 33.2 to 37.8 on seen objects and from 8.2 to 17.1 on unseen objects. Furthermore, we demonstrate more accurate shape predictions without closely matching CAD models when following the proposed shape adaptation. Code is publicly available at https://github.com/florianlanger/leveraging_geometry_for_shape_estimation .
PDF Abstract

 Pix3D
Pix3D
