LexSubCon: Integrating Knowledge from Lexical Resources into Contextual Embeddings for Lexical Substitution
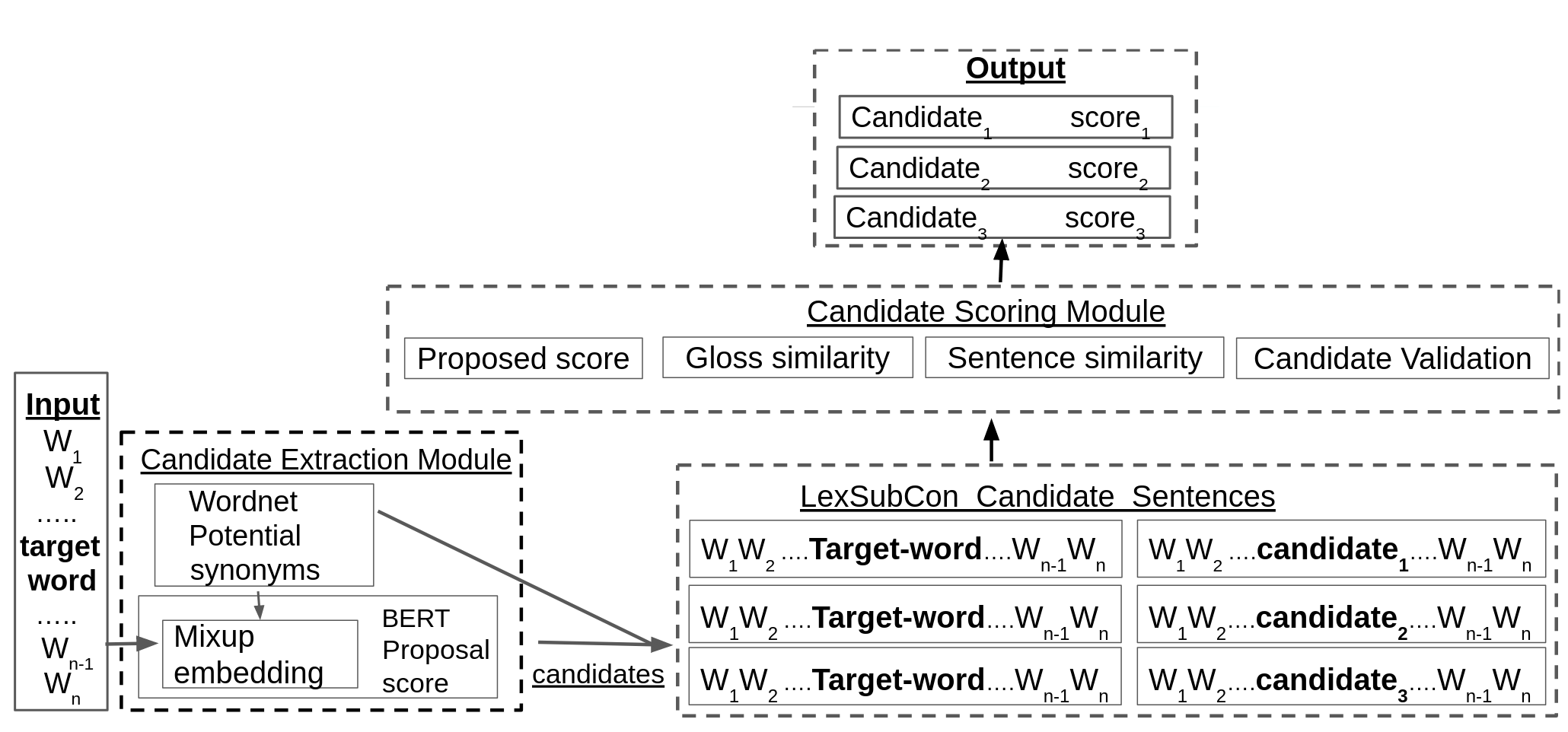
Lexical substitution is the task of generating meaningful substitutes for a word in a given textual context. Contextual word embedding models have achieved state-of-the-art results in the lexical substitution task by relying on contextual information extracted from the replaced word within the sentence. However, such models do not take into account structured knowledge that exists in external lexical databases. We introduce LexSubCon, an end-to-end lexical substitution framework based on contextual embedding models that can identify highly accurate substitute candidates. This is achieved by combining contextual information with knowledge from structured lexical resources. Our approach involves: (i) introducing a novel mix-up embedding strategy in the creation of the input embedding of the target word through linearly interpolating the pair of the target input embedding and the average embedding of its probable synonyms; (ii) considering the similarity of the sentence-definition embeddings of the target word and its proposed candidates; and, (iii) calculating the effect of each substitution in the semantics of the sentence through a fine-tuned sentence similarity model. Our experiments show that LexSubCon outperforms previous state-of-the-art methods on LS07 and CoInCo benchmark datasets that are widely used for lexical substitution tasks.
PDF Abstract ACL 2022 PDF ACL 2022 Abstract

