KGLiDS: A Platform for Semantic Abstraction, Linking, and Automation of Data Science
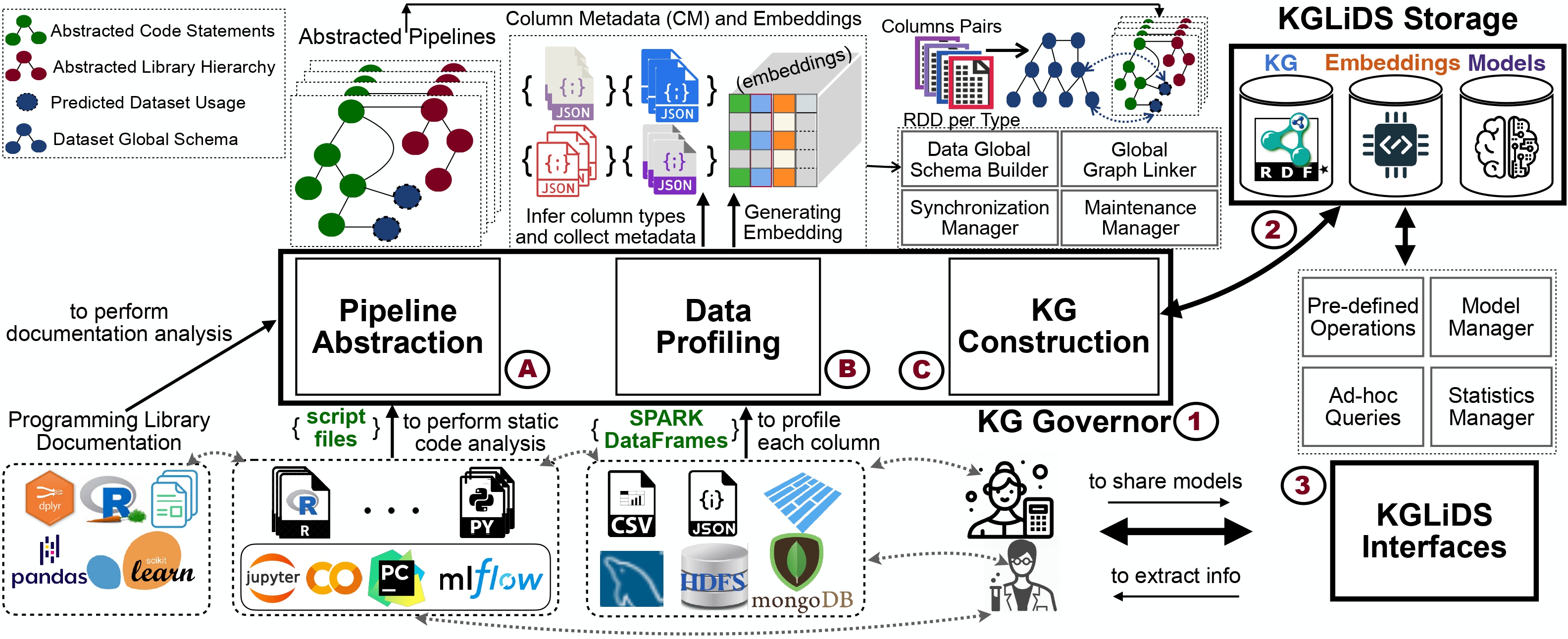
In recent years, we have witnessed the growing interest from academia and industry in applying data science technologies to analyze large amounts of data. In this process, a myriad of artifacts (datasets, pipeline scripts, etc.) are created. However, there has been no systematic attempt to holistically collect and exploit all the knowledge and experiences that are implicitly contained in those artifacts. Instead, data scientists recover information and expertise from colleagues or learn via trial and error. Hence, this paper presents a scalable platform, KGLiDS, that employs machine learning and knowledge graph technologies to abstract and capture the semantics of data science artifacts and their connections. Based on this information, KGLiDS enables various downstream applications, such as data discovery and pipeline automation. Our comprehensive evaluation covers use cases in data discovery, data cleaning, transformation, and AutoML. It shows that KGLiDS is significantly faster with a lower memory footprint than the state-of-the-art systems while achieving comparable or better accuracy.
PDF Abstract Colab
Colab


