LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning
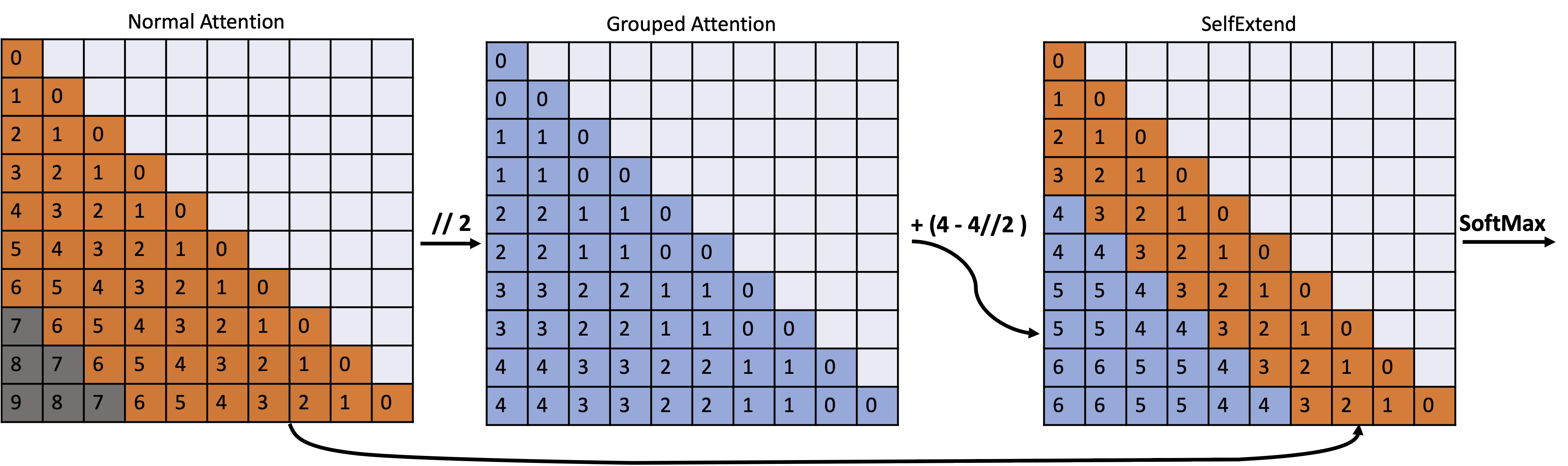
It is well known that LLMs cannot generalize well to long contexts whose lengths are larger than the training sequence length. This poses challenges when employing LLMs for processing long input sequences during inference. In this work, we argue that LLMs themselves have inherent capabilities to handle long contexts without fine-tuning. To achieve this goal, we propose SelfExtend to extend the context window of LLMs by constructing bi-level attention information: the grouped attention and the neighbor attention. The grouped attention captures the dependencies among tokens that are far apart, while neighbor attention captures dependencies among adjacent tokens within a specified range. The two-level attentions are computed based on the original model's self-attention mechanism during inference. With minor code modification, our SelfExtend can effortlessly extend existing LLMs' context window without any fine-tuning. We conduct comprehensive experiments on multiple benchmarks and the results show that our SelfExtend can effectively extend existing LLMs' context window length. The code can be found at \url{https://github.com/datamllab/LongLM}.
PDF Abstract
 MMLU
MMLU
 GSM8K
GSM8K
 HellaSwag
HellaSwag
 TruthfulQA
TruthfulQA
