LLMs with Chain-of-Thought Are Non-Causal Reasoners
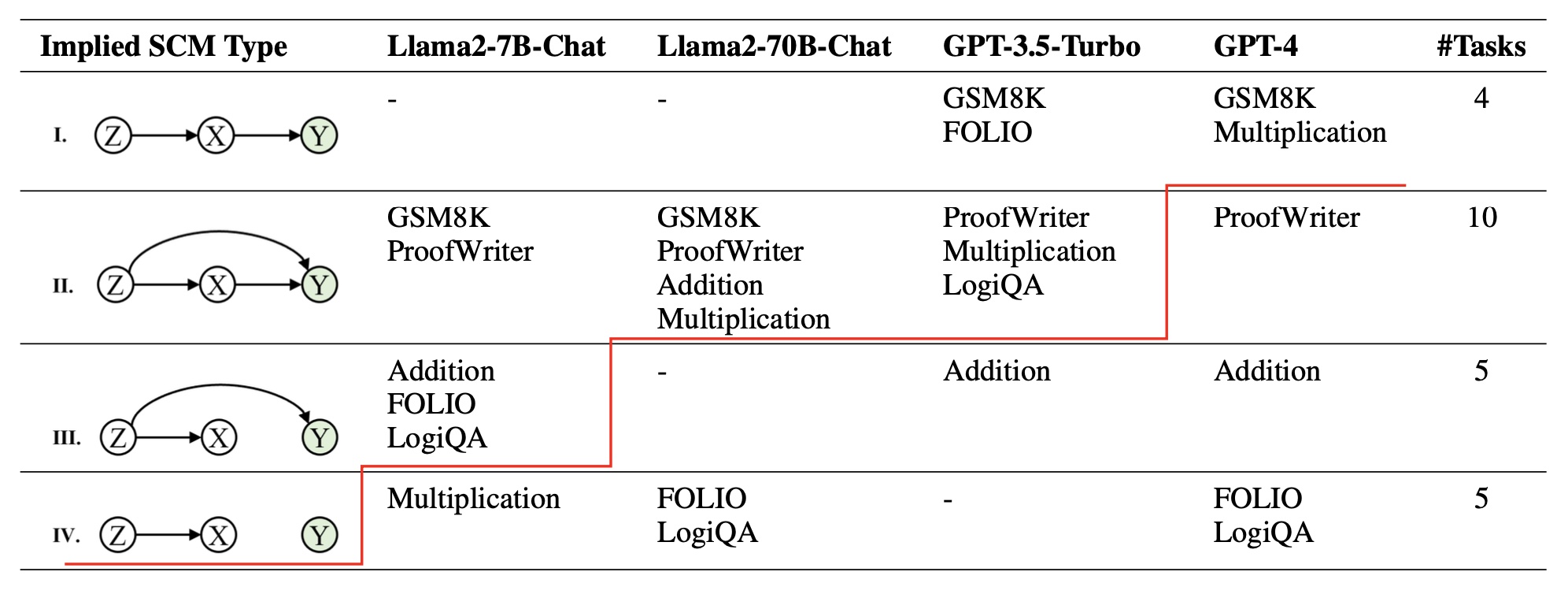
This paper explores the role of the Chain of Thought (CoT) in Large Language Models (LLMs) reasoning. Despite its potential to improve task performance, our analysis reveals a surprising frequency of correct answers following incorrect CoTs and vice versa. We employ causal analysis to assess the cause-effect relationship between CoTs/instructions and answers in LLMs, uncovering the Structural Causal Model (SCM) that LLMs approximate. By comparing the implied SCM with that of human reasoning, we highlight discrepancies between LLM and human reasoning processes. We further examine the factors influencing the causal structure of the implied SCM, revealing that in-context learning, supervised fine-tuning, and reinforcement learning on human feedback significantly impact the causal relations. We release the code and results at https://github.com/StevenZHB/CoT_Causal_Analysis.
PDF Abstract
 GSM8K
GSM8K
 ProofWriter
ProofWriter
