Local Explanation Methods for Deep Neural Networks Lack Sensitivity to Parameter Values
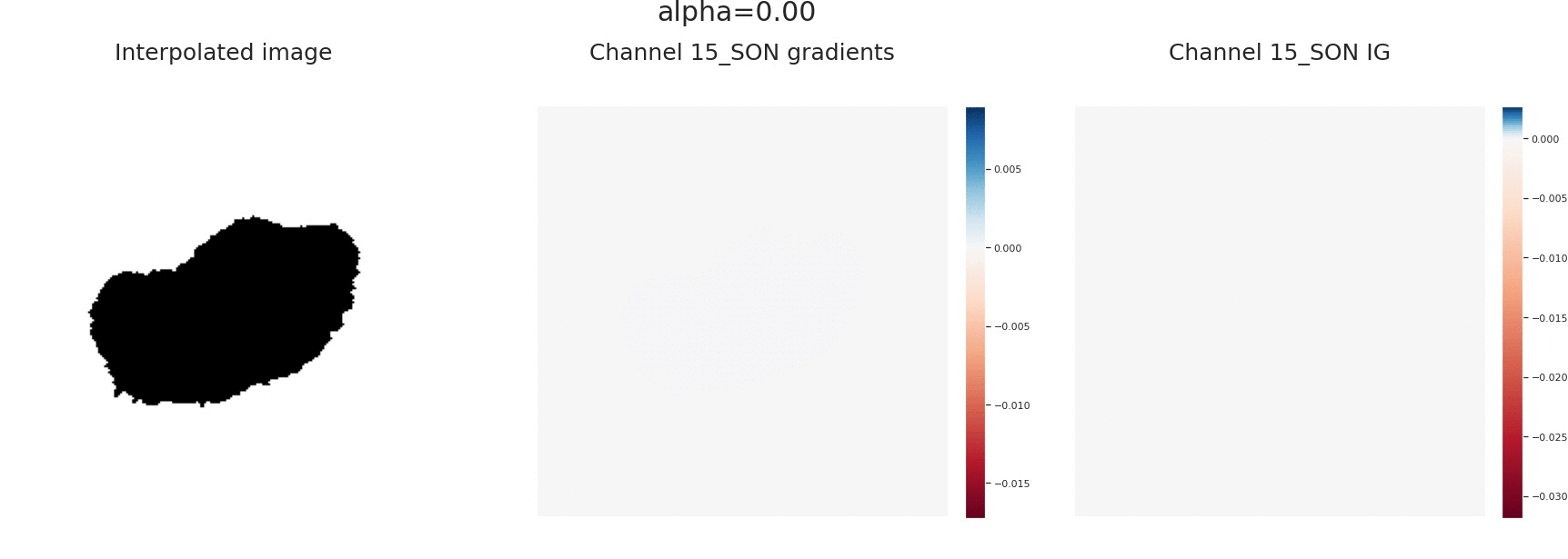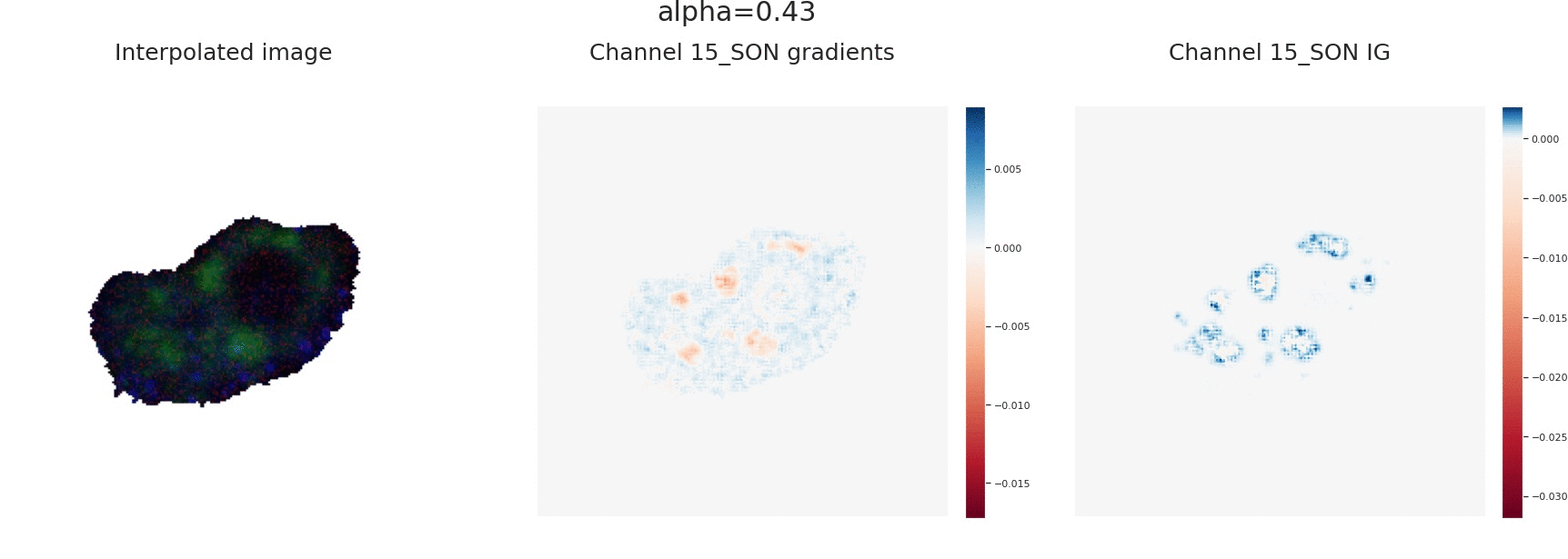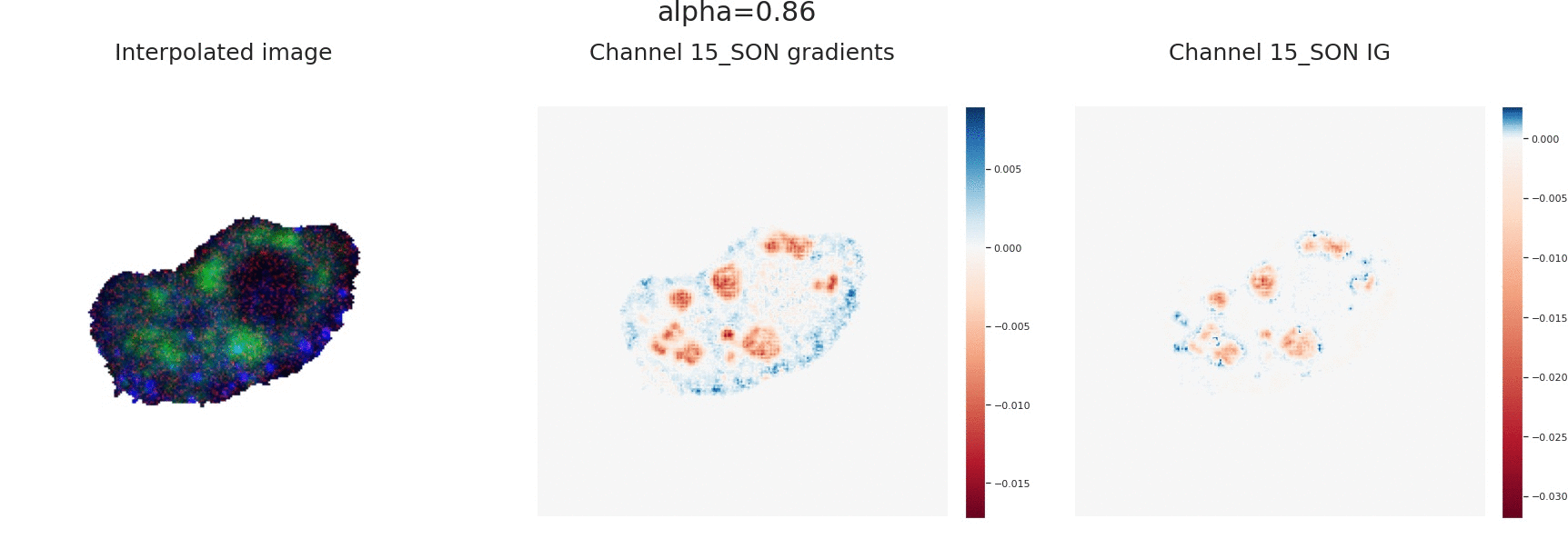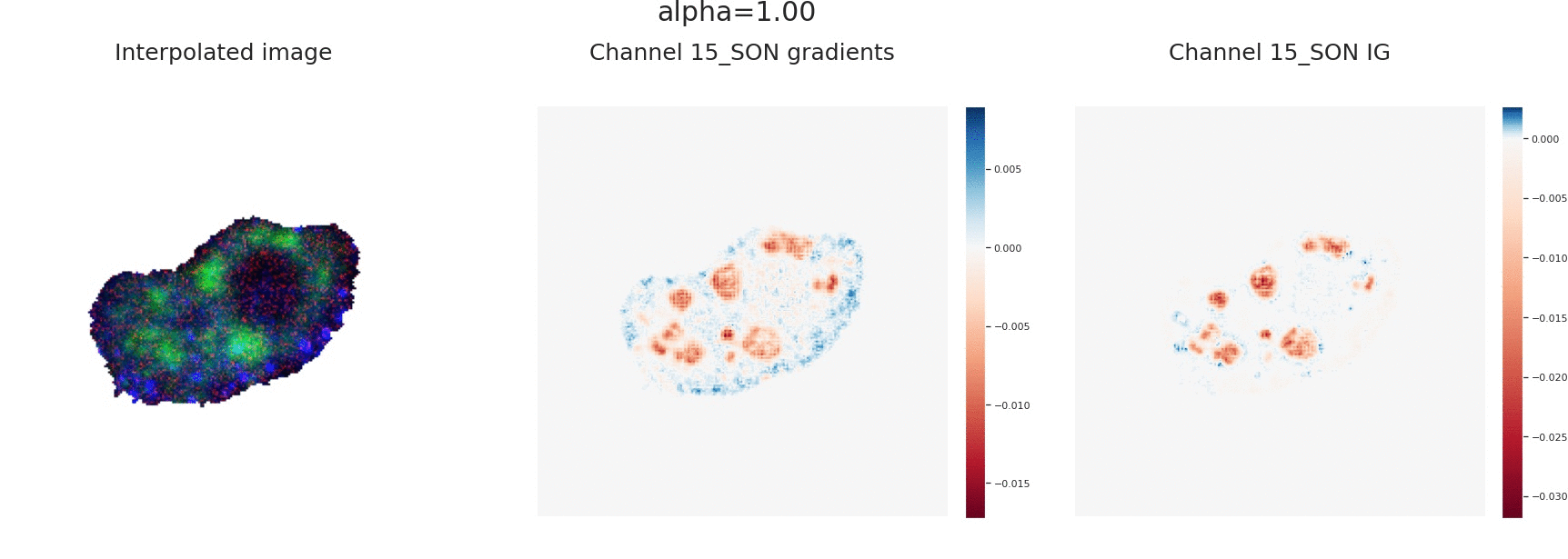
Explaining the output of a complicated machine learning model like a deep neural network (DNN) is a central challenge in machine learning. Several proposed local explanation methods address this issue by identifying what dimensions of a single input are most responsible for a DNN's output. The goal of this work is to assess the sensitivity of local explanations to DNN parameter values. Somewhat surprisingly, we find that DNNs with randomly-initialized weights produce explanations that are both visually and quantitatively similar to those produced by DNNs with learned weights. Our conjecture is that this phenomenon occurs because these explanations are dominated by the lower level features of a DNN, and that a DNN's architecture provides a strong prior which significantly affects the representations learned at these lower layers. NOTE: This work is now subsumed by our recent manuscript, Sanity Checks for Saliency Maps (to appear NIPS 2018), where we expand on findings and address concerns raised in Sundararajan et. al. (2018).
PDF Abstract


