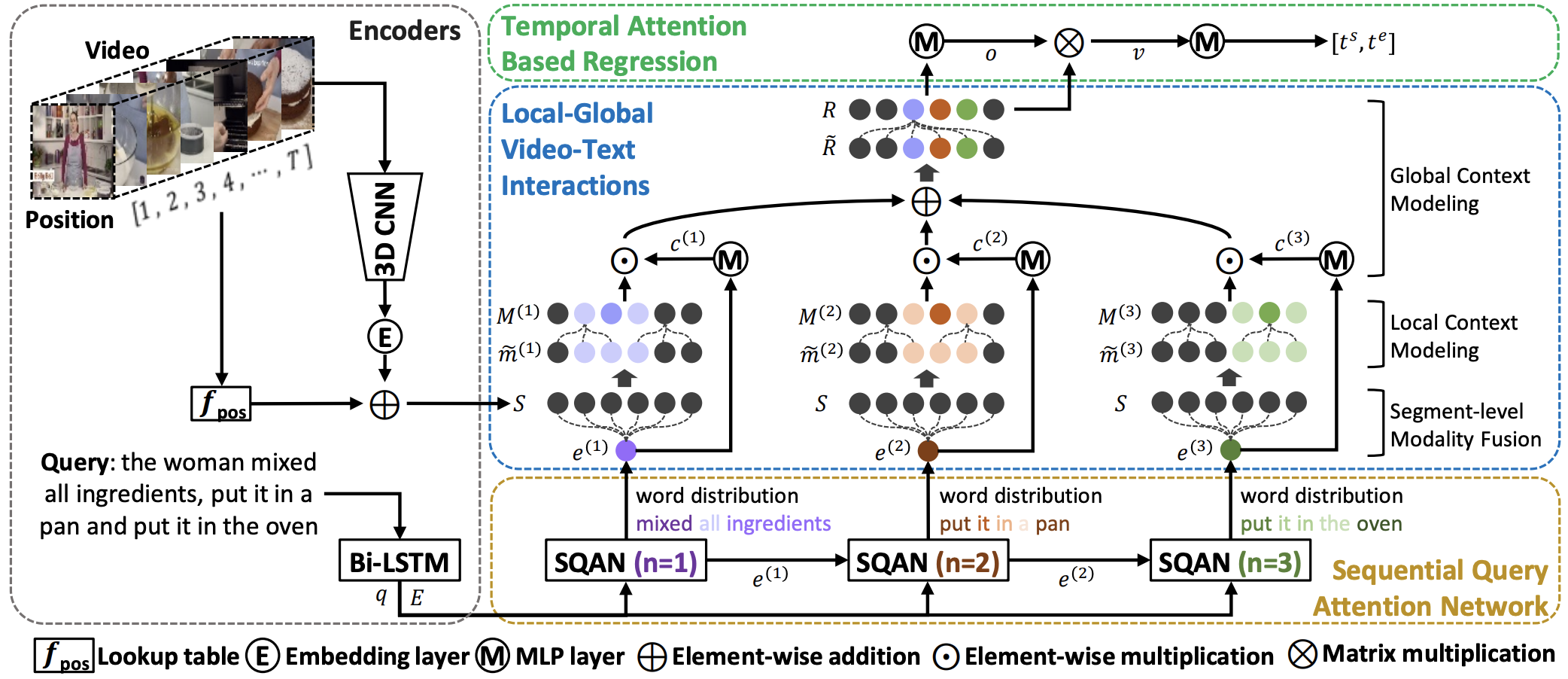
Local-Global Video-Text Interactions for Temporal Grounding
This paper addresses the problem of text-to-video temporal grounding, which aims to identify the time interval in a video semantically relevant to a text query. We tackle this problem using a novel regression-based model that learns to extract a collection of mid-level features for semantic phrases in a text query, which corresponds to important semantic entities described in the query (e.g., actors, objects, and actions), and reflect bi-modal interactions between the linguistic features of the query and the visual features of the video in multiple levels. The proposed method effectively predicts the target time interval by exploiting contextual information from local to global during bi-modal interactions. Through in-depth ablation studies, we find out that incorporating both local and global context in video and text interactions is crucial to the accurate grounding. Our experiment shows that the proposed method outperforms the state of the arts on Charades-STA and ActivityNet Captions datasets by large margins, 7.44\% and 4.61\% points at Recall@tIoU=0.5 metric, respectively. Code is available in https://github.com/JonghwanMun/LGI4temporalgrounding.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract
 ActivityNet
ActivityNet
 ActivityNet Captions
ActivityNet Captions
 Charades-STA
Charades-STA
