Localizing Visual Sounds the Easy Way
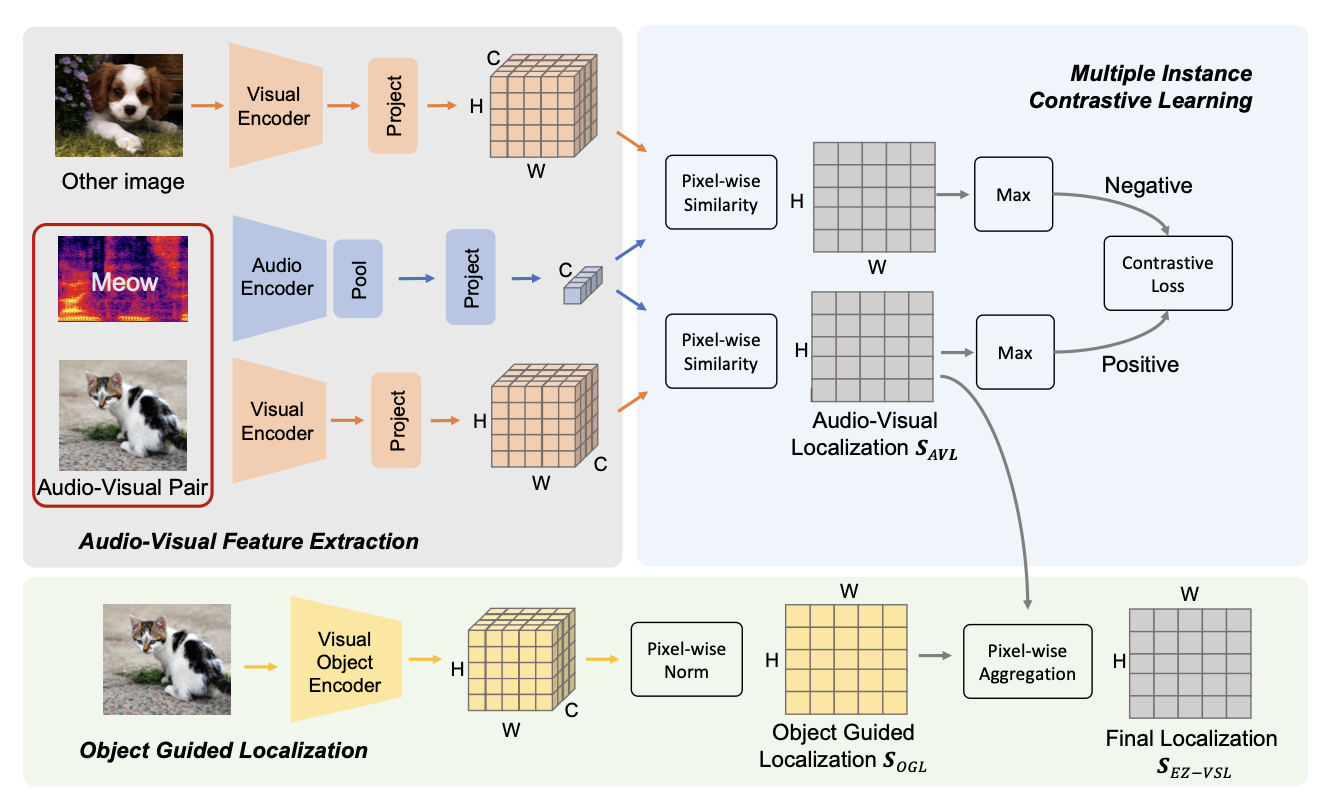
Unsupervised audio-visual source localization aims at localizing visible sound sources in a video without relying on ground-truth localization for training. Previous works often seek high audio-visual similarities for likely positive (sounding) regions and low similarities for likely negative regions. However, accurately distinguishing between sounding and non-sounding regions is challenging without manual annotations. In this work, we propose a simple yet effective approach for Easy Visual Sound Localization, namely EZ-VSL, without relying on the construction of positive and/or negative regions during training. Instead, we align audio and visual spaces by seeking audio-visual representations that are aligned in, at least, one location of the associated image, while not matching other images, at any location. We also introduce a novel object guided localization scheme at inference time for improved precision. Our simple and effective framework achieves state-of-the-art performance on two popular benchmarks, Flickr SoundNet and VGG-Sound Source. In particular, we improve the CIoU of the Flickr SoundNet test set from 76.80% to 83.94%, and on the VGG-Sound Source dataset from 34.60% to 38.85%. The code is available at https://github.com/stoneMo/EZ-VSL.
PDF Abstract
 ImageNet
ImageNet
 VGG-Sound
VGG-Sound
 VGG-SS
VGG-SS
