Masked Conditional Neural Networks for Audio Classification
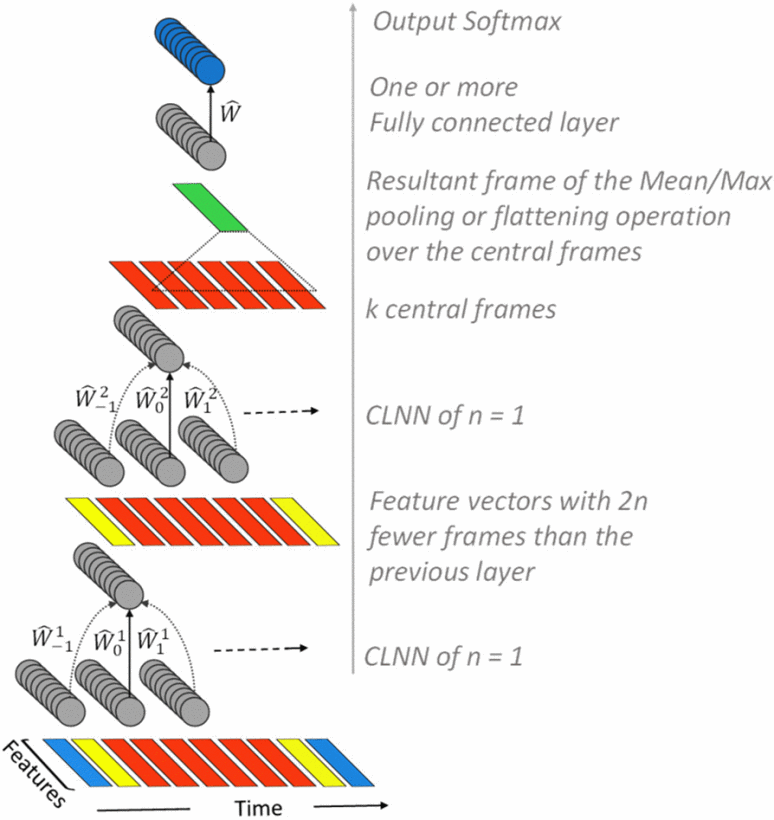
We present the ConditionaL Neural Network (CLNN) and the Masked ConditionaL Neural Network (MCLNN) designed for temporal signal recognition. The CLNN takes into consideration the temporal nature of the sound signal and the MCLNN extends upon the CLNN through a binary mask to preserve the spatial locality of the features and allows an automated exploration of the features combination analogous to hand-crafting the most relevant features for the recognition task. MCLNN has achieved competitive recognition accuracies on the GTZAN and the ISMIR2004 music datasets that surpass several state-of-the-art neural network based architectures and hand-crafted methods applied on both datasets.
PDF Abstract



Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
