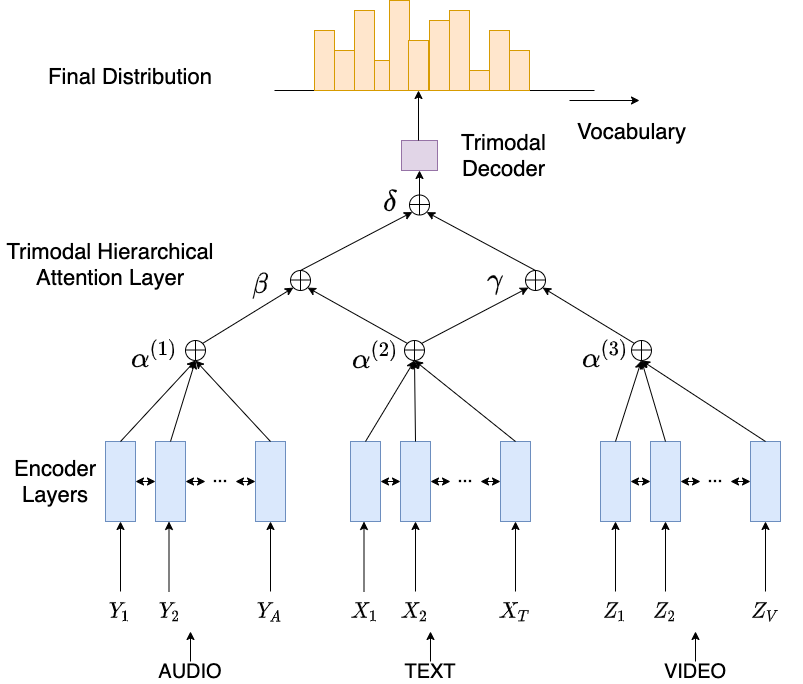
MAST: Multimodal Abstractive Summarization with Trimodal Hierarchical Attention
This paper presents MAST, a new model for Multimodal Abstractive Text Summarization that utilizes information from all three modalities -- text, audio and video -- in a multimodal video. Prior work on multimodal abstractive text summarization only utilized information from the text and video modalities. We examine the usefulness and challenges of deriving information from the audio modality and present a sequence-to-sequence trimodal hierarchical attention-based model that overcomes these challenges by letting the model pay more attention to the text modality. MAST outperforms the current state of the art model (video-text) by 2.51 points in terms of Content F1 score and 1.00 points in terms of Rouge-L score on the How2 dataset for multimodal language understanding.
PDF Abstract EMNLP (nlpbt) 2020 PDF EMNLP (nlpbt) 2020 Abstract



 How2
How2

