MediaSum: A Large-scale Media Interview Dataset for Dialogue Summarization
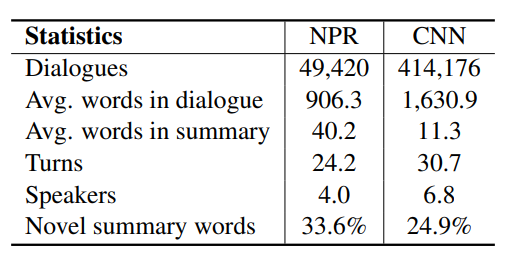
MediaSum, a large-scale media interview dataset consisting of 463.6K transcripts with abstractive summaries. To create this dataset, we collect interview transcripts from NPR and CNN and employ the overview and topic descriptions as summaries. Compared with existing public corpora for dialogue summarization, our dataset is an order of magnitude larger and contains complex multi-party conversations from multiple domains. We conduct statistical analysis to demonstrate the unique positional bias exhibited in the transcripts of televised and radioed interviews. We also show that MediaSum can be used in transfer learning to improve a model's performance on other dialogue summarization tasks.
PDF Abstract NAACL 2021 PDF NAACL 2021 AbstractCode
Tasks

 MultiWOZ
MultiWOZ
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
