Mesh Graphormer
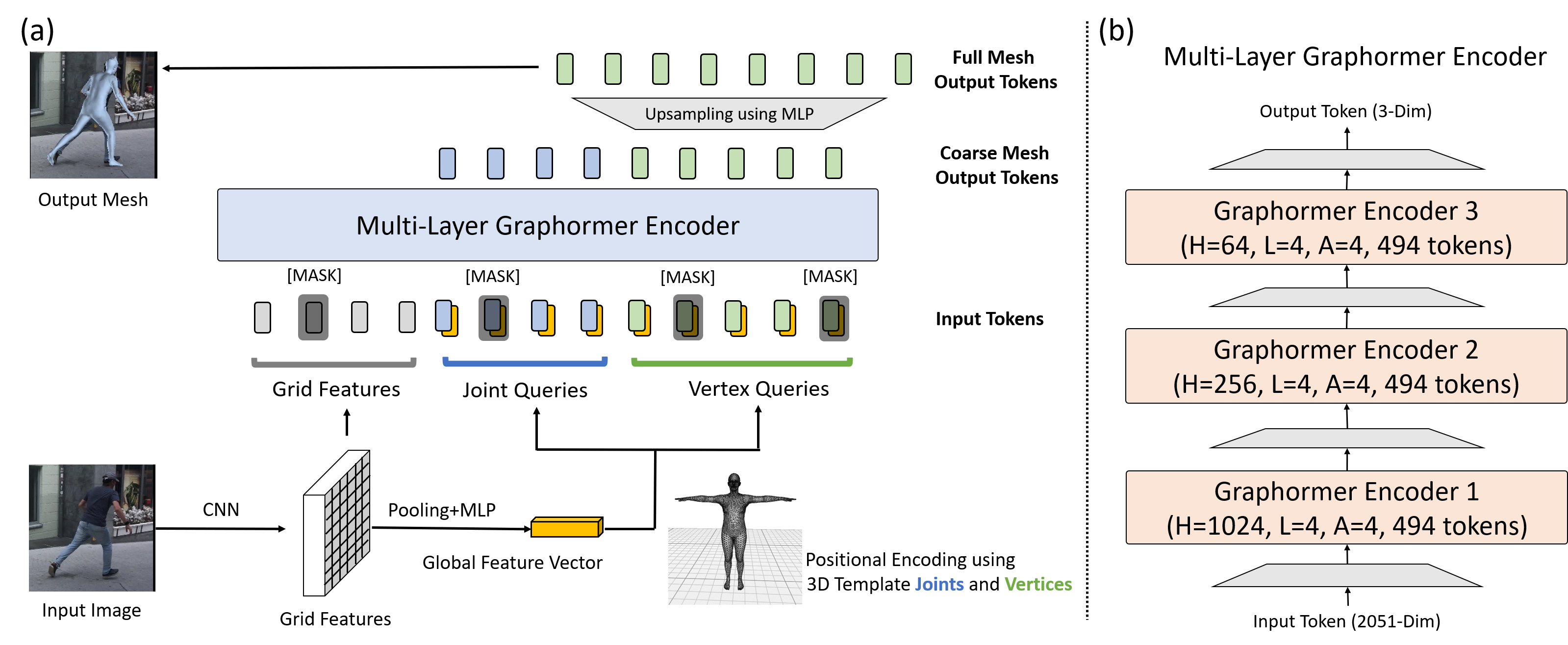
We present a graph-convolution-reinforced transformer, named Mesh Graphormer, for 3D human pose and mesh reconstruction from a single image. Recently both transformers and graph convolutional neural networks (GCNNs) have shown promising progress in human mesh reconstruction. Transformer-based approaches are effective in modeling non-local interactions among 3D mesh vertices and body joints, whereas GCNNs are good at exploiting neighborhood vertex interactions based on a pre-specified mesh topology. In this paper, we study how to combine graph convolutions and self-attentions in a transformer to model both local and global interactions. Experimental results show that our proposed method, Mesh Graphormer, significantly outperforms the previous state-of-the-art methods on multiple benchmarks, including Human3.6M, 3DPW, and FreiHAND datasets. Code and pre-trained models are available at https://github.com/microsoft/MeshGraphormer
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract

 Human3.6M
Human3.6M
 3DPW
3DPW
 FreiHAND
FreiHAND

