MetaIE: Distilling a Meta Model from LLM for All Kinds of Information Extraction Tasks
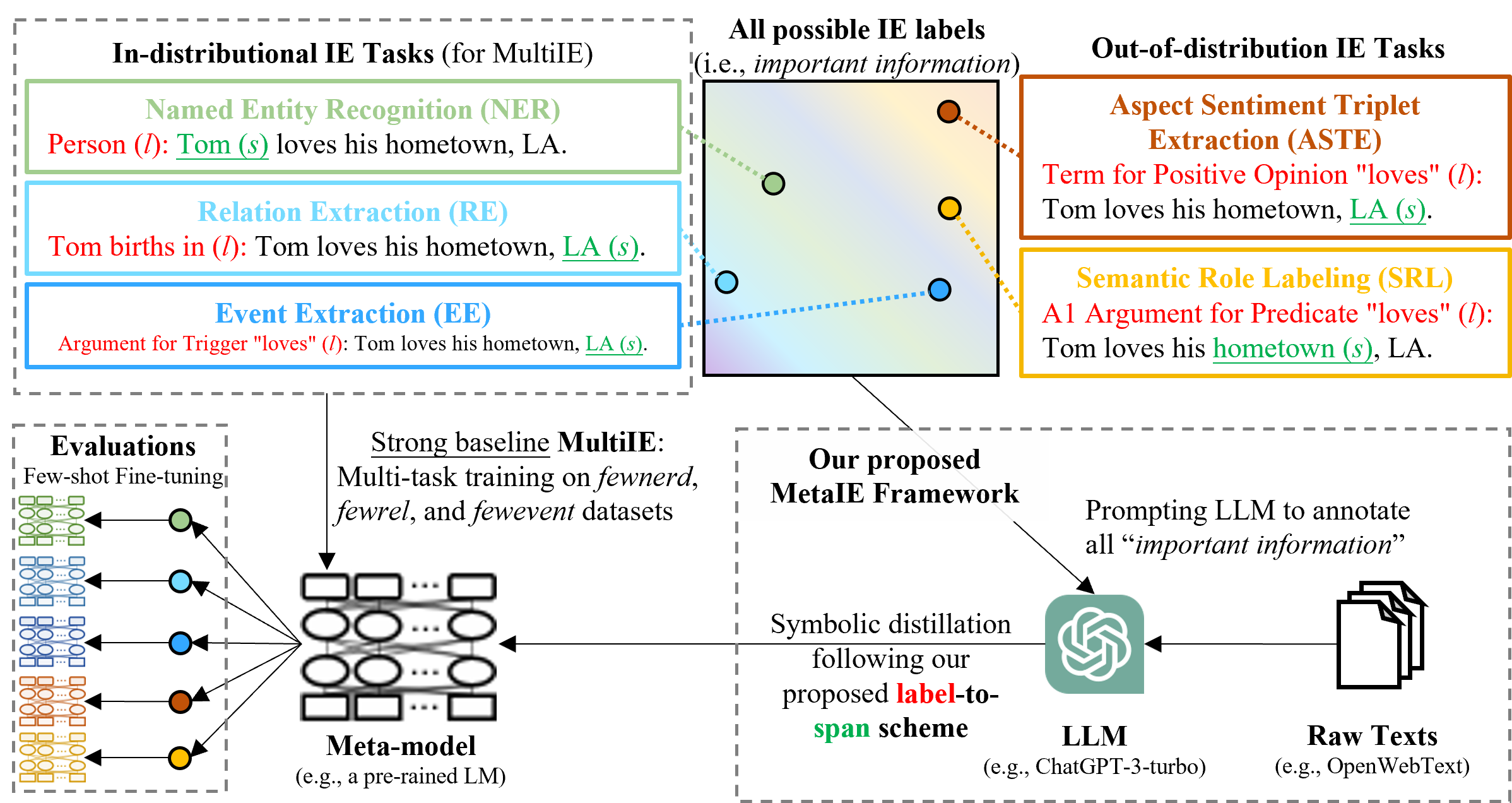
Information extraction (IE) is a fundamental area in natural language processing where prompting large language models (LLMs), even with in-context examples, cannot defeat small LMs tuned on very small IE datasets. We observe that IE tasks, such as named entity recognition and relation extraction, all focus on extracting important information, which can be formalized as a label-to-span matching. In this paper, we propose a novel framework MetaIE to build a small LM as meta-model by learning to extract "important information", i.e., the meta-understanding of IE, so that this meta-model can be adapted to all kind of IE tasks effectively and efficiently. Specifically, MetaIE obtains the small LM via a symbolic distillation from an LLM following the label-to-span scheme. We construct the distillation dataset via sampling sentences from language model pre-training datasets (e.g., OpenWebText in our implementation) and prompting an LLM to identify the typed spans of "important information". We evaluate the meta-model under the few-shot adaptation setting. Extensive results on 13 datasets from 6 IE tasks confirm that MetaIE can offer a better starting point for few-shot tuning on IE datasets and outperform other meta-models from (1) vanilla language model pre-training, (2) multi-IE-task pre-training with human annotations, and (3) single-IE-task symbolic distillation from LLM. Moreover, we provide comprehensive analyses of MetaIE, such as the size of the distillation dataset, the meta-model architecture, and the size of the meta-model.
PDF Abstract



 Few-NERD
Few-NERD
