MIM: Mutual Information Machine
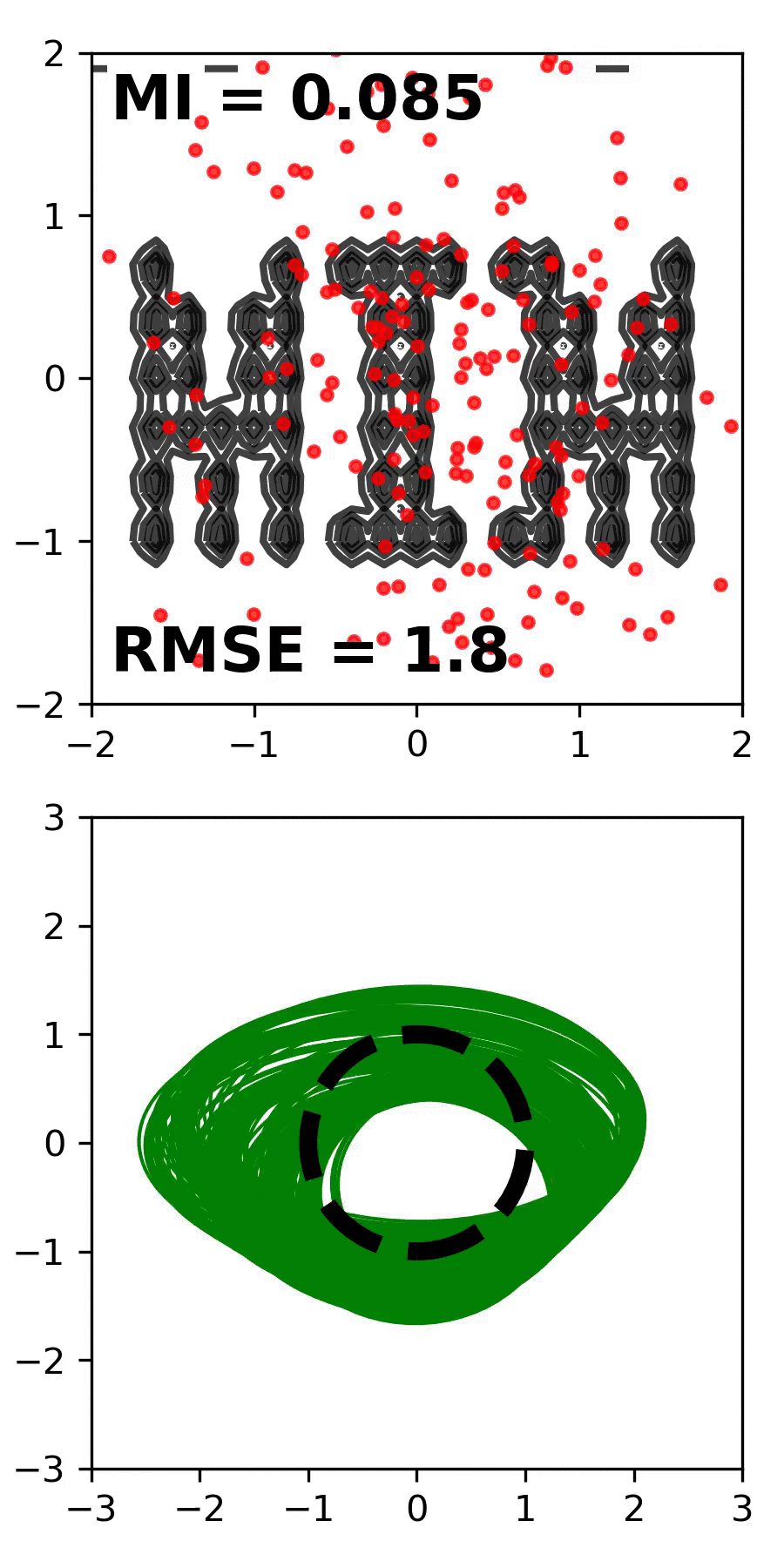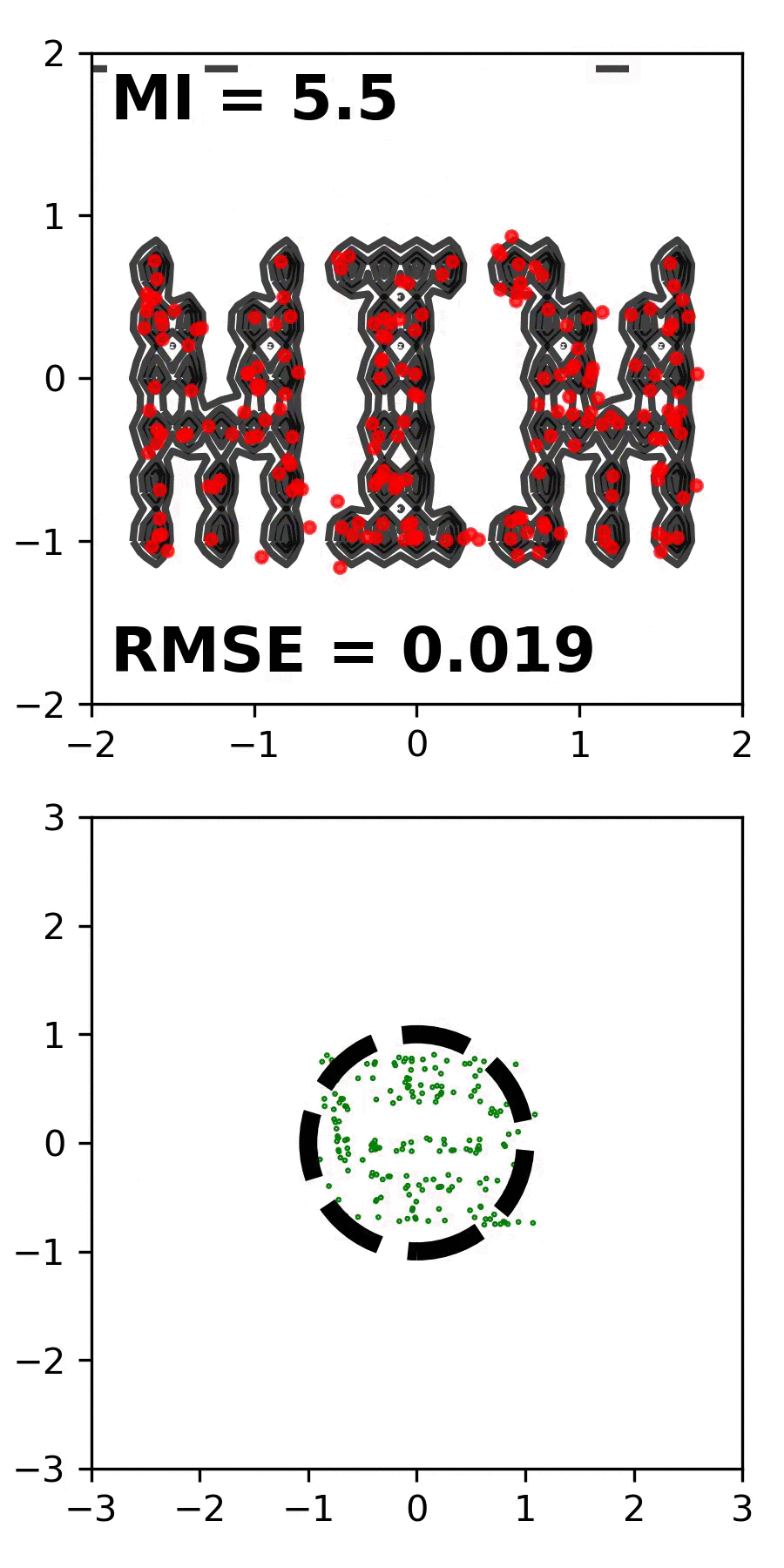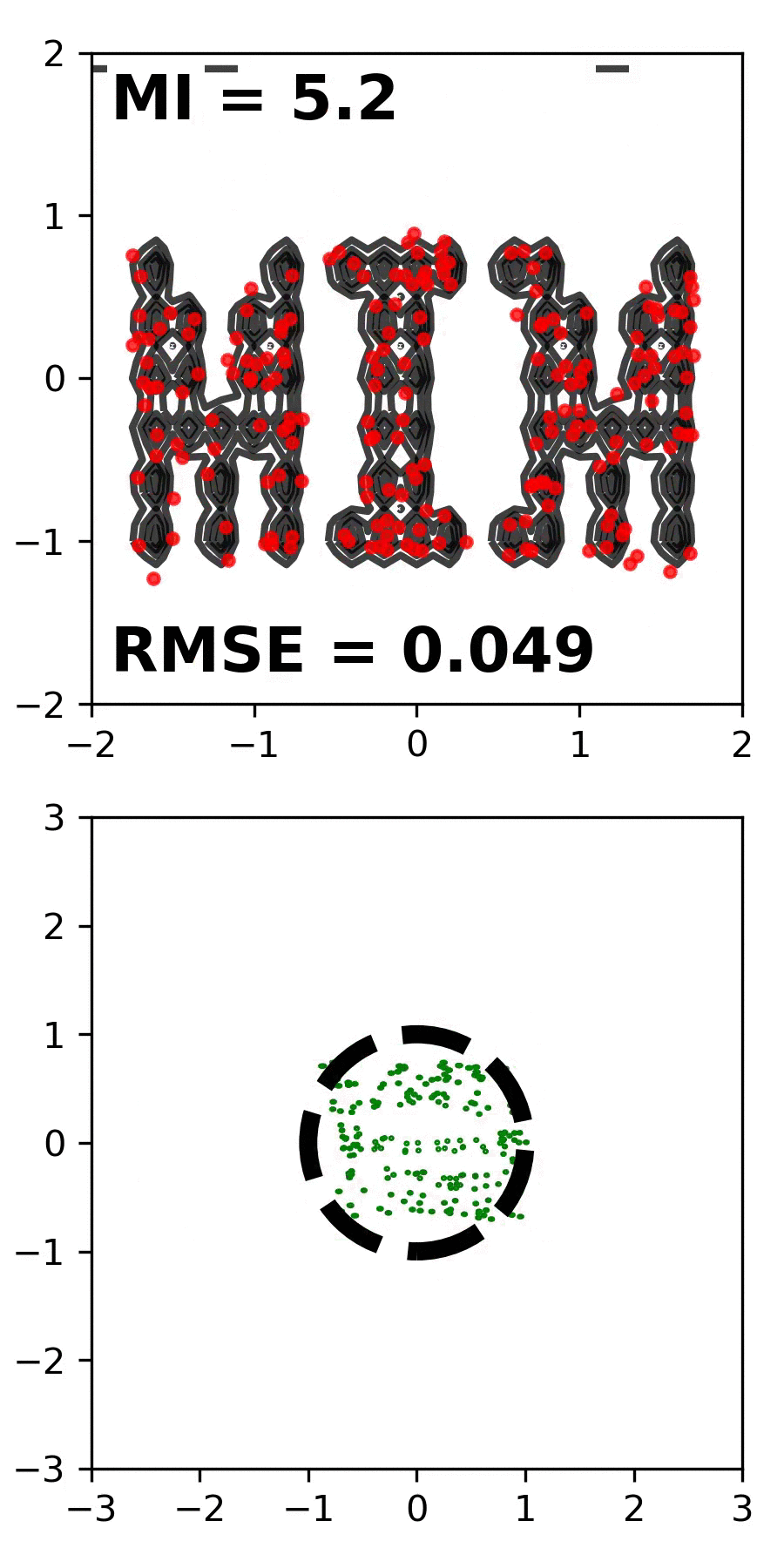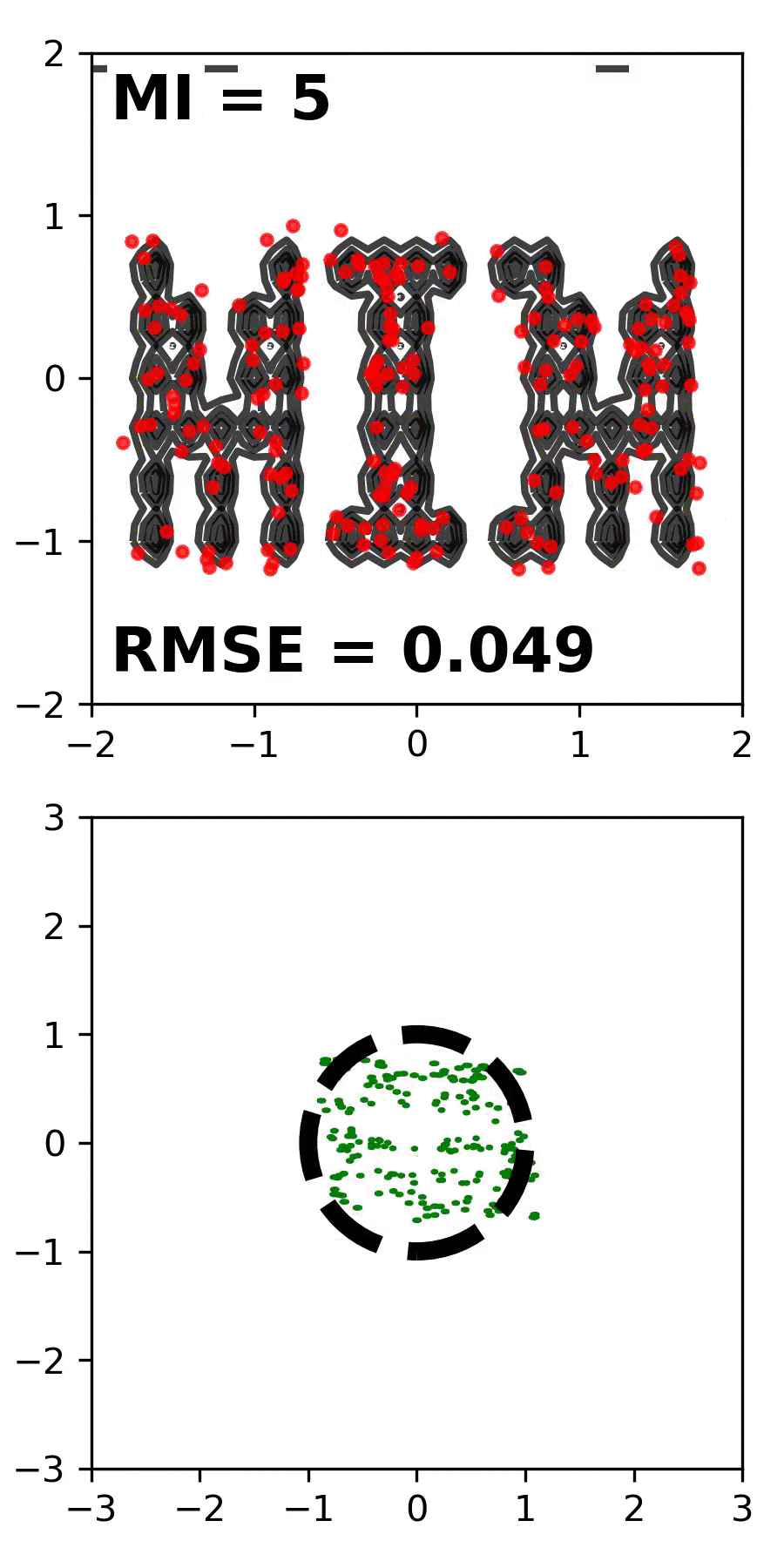
We introduce the Mutual Information Machine (MIM), a probabilistic auto-encoder for learning joint distributions over observations and latent variables. MIM reflects three design principles: 1) low divergence, to encourage the encoder and decoder to learn consistent factorizations of the same underlying distribution; 2) high mutual information, to encourage an informative relation between data and latent variables; and 3) low marginal entropy, or compression, which tends to encourage clustered latent representations. We show that a combination of the Jensen-Shannon divergence and the joint entropy of the encoding and decoding distributions satisfies these criteria, and admits a tractable cross-entropy bound that can be optimized directly with Monte Carlo and stochastic gradient descent. We contrast MIM learning with maximum likelihood and VAEs. Experiments show that MIM learns representations with high mutual information, consistent encoding and decoding distributions, effective latent clustering, and data log likelihood comparable to VAE, while avoiding posterior collapse.
PDF Abstract

 Fashion-MNIST
Fashion-MNIST
