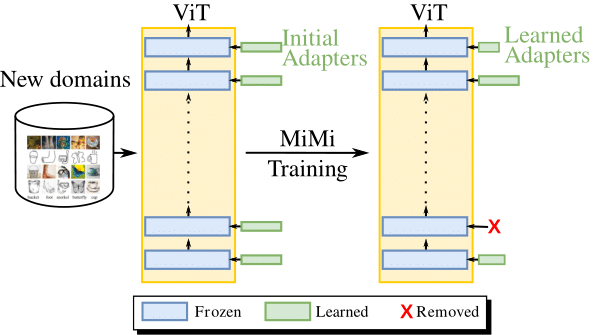
Mini but Mighty: Finetuning ViTs with Mini Adapters
Vision Transformers (ViTs) have become one of the dominant architectures in computer vision, and pre-trained ViT models are commonly adapted to new tasks via fine-tuning. Recent works proposed several parameter-efficient transfer learning methods, such as adapters, to avoid the prohibitive training and storage cost of finetuning. In this work, we observe that adapters perform poorly when the dimension of adapters is small, and we propose MiMi, a training framework that addresses this issue. We start with large adapters which can reach high performance, and iteratively reduce their size. To enable automatic estimation of the hidden dimension of every adapter, we also introduce a new scoring function, specifically designed for adapters, that compares the neuron importance across layers. Our method outperforms existing methods in finding the best trade-off between accuracy and trained parameters across the three dataset benchmarks DomainNet, VTAB, and Multi-task, for a total of 29 datasets.
PDF Abstract

 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 SVHN
SVHN
 Oxford 102 Flower
Oxford 102 Flower
