MIntRec: A New Dataset for Multimodal Intent Recognition
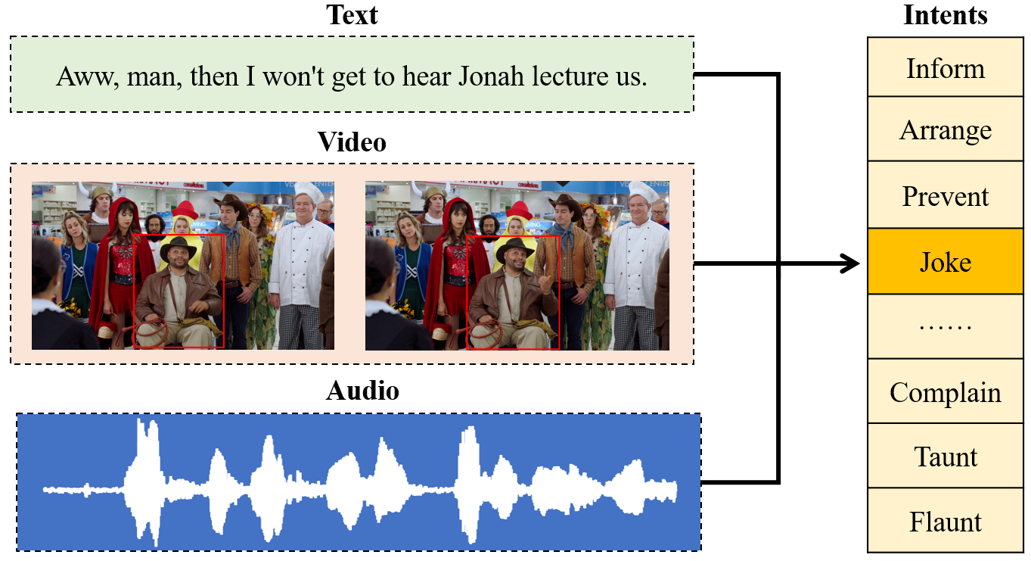
Multimodal intent recognition is a significant task for understanding human language in real-world multimodal scenes. Most existing intent recognition methods have limitations in leveraging the multimodal information due to the restrictions of the benchmark datasets with only text information. This paper introduces a novel dataset for multimodal intent recognition (MIntRec) to address this issue. It formulates coarse-grained and fine-grained intent taxonomies based on the data collected from the TV series Superstore. The dataset consists of 2,224 high-quality samples with text, video, and audio modalities and has multimodal annotations among twenty intent categories. Furthermore, we provide annotated bounding boxes of speakers in each video segment and achieve an automatic process for speaker annotation. MIntRec is helpful for researchers to mine relationships between different modalities to enhance the capability of intent recognition. We extract features from each modality and model cross-modal interactions by adapting three powerful multimodal fusion methods to build baselines. Extensive experiments show that employing the non-verbal modalities achieves substantial improvements compared with the text-only modality, demonstrating the effectiveness of using multimodal information for intent recognition. The gap between the best-performing methods and humans indicates the challenge and importance of this task for the community. The full dataset and codes are available for use at https://github.com/thuiar/MIntRec.
PDF Abstract


 MIntRec
MIntRec
 MDID
MDID

