MixerGAN: An MLP-Based Architecture for Unpaired Image-to-Image Translation
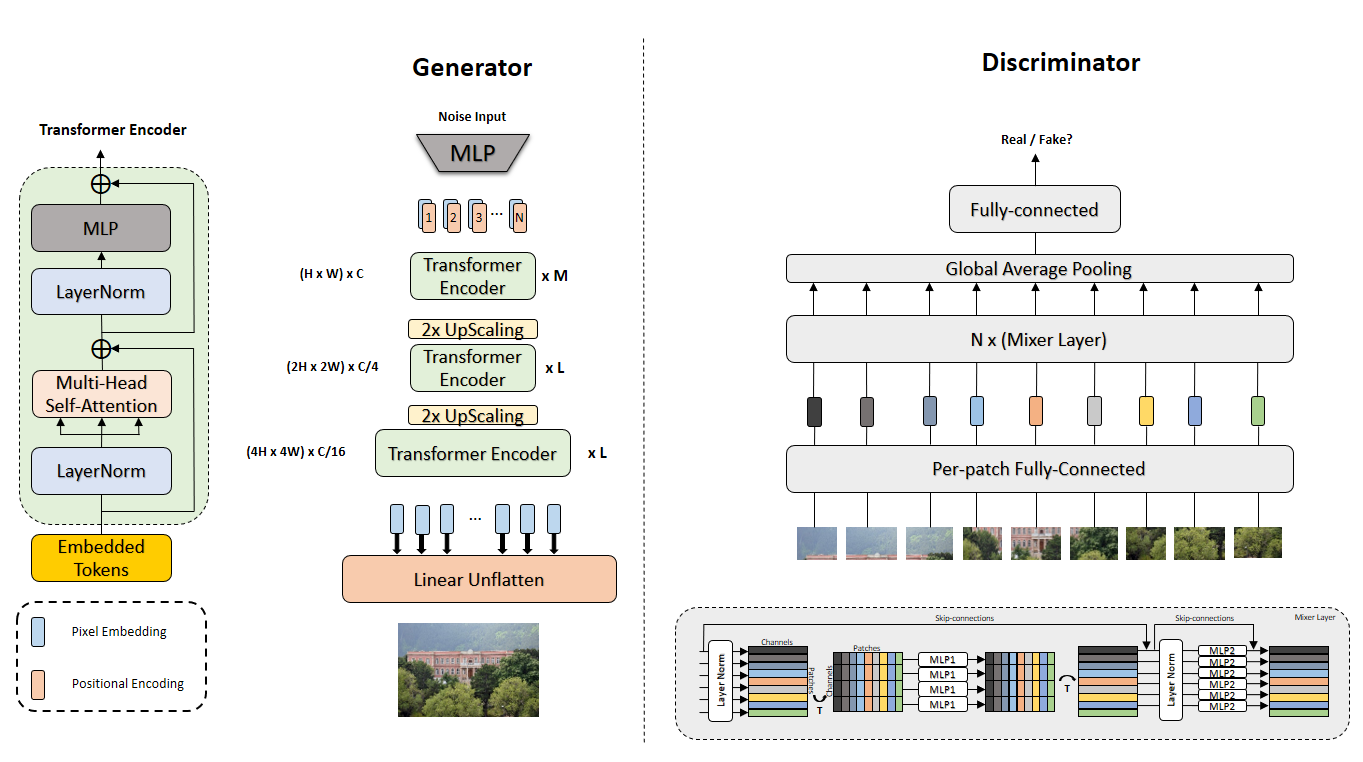
While attention-based transformer networks achieve unparalleled success in nearly all language tasks, the large number of tokens (pixels) found in images coupled with the quadratic activation memory usage makes them prohibitive for problems in computer vision. As such, while language-to-language translation has been revolutionized by the transformer model, convolutional networks remain the de facto solution for image-to-image translation. The recently proposed MLP-Mixer architecture alleviates some of the computational issues associated with attention-based networks while still retaining the long-range connections that make transformer models desirable. Leveraging this memory-efficient alternative to self-attention, we propose a new exploratory model in unpaired image-to-image translation called MixerGAN: a simpler MLP-based architecture that considers long-distance relationships between pixels without the need for expensive attention mechanisms. Quantitative and qualitative analysis shows that MixerGAN achieves competitive results when compared to prior convolutional-based methods.
PDF Abstract


