Continuous Deep Equilibrium Models: Training Neural ODEs faster by integrating them to Infinity
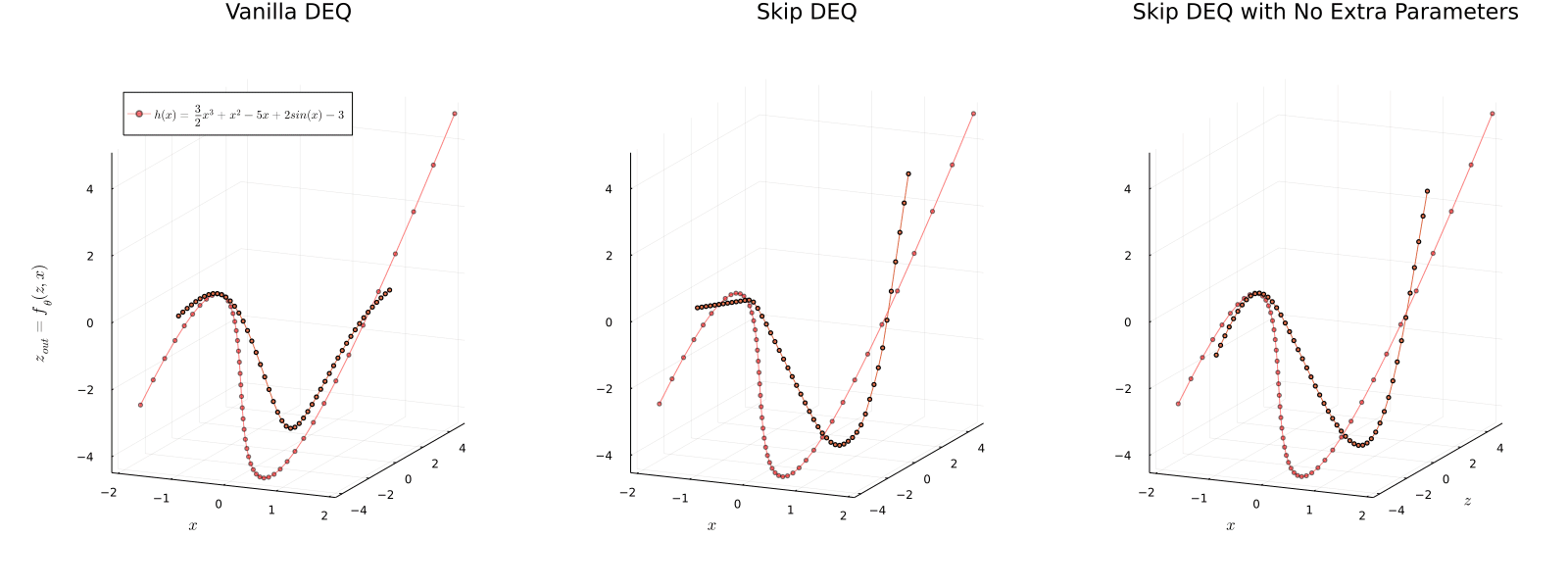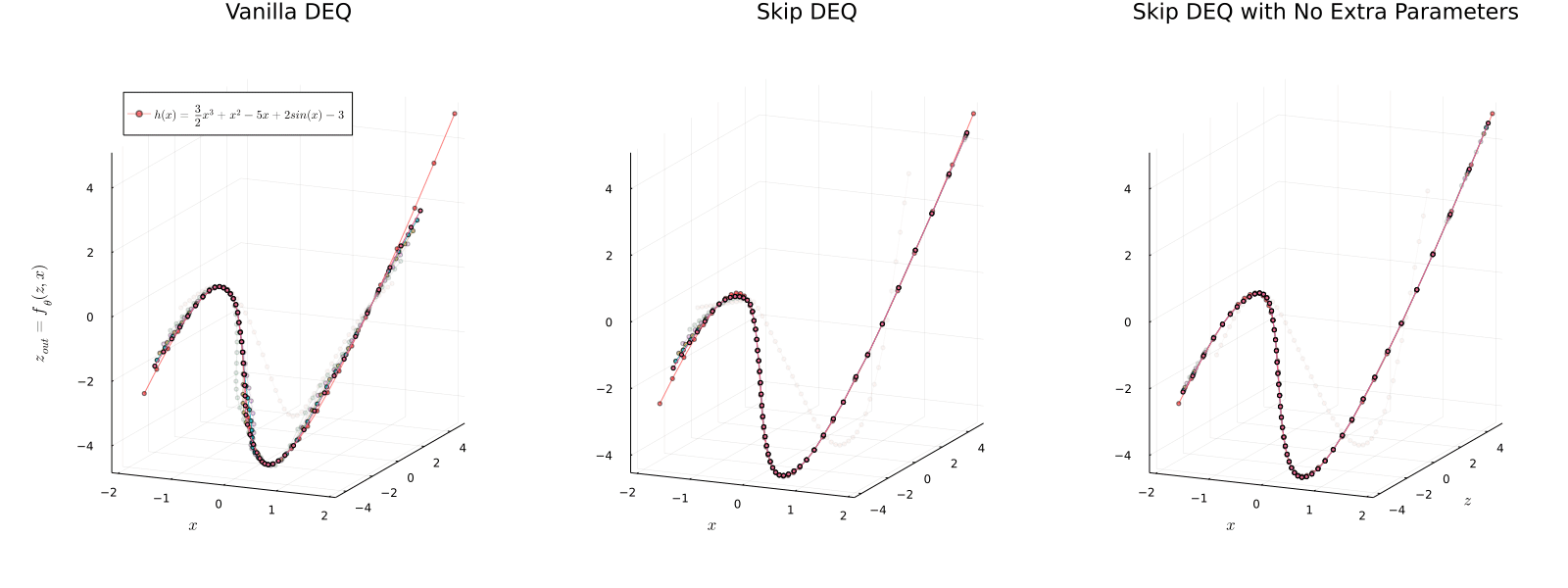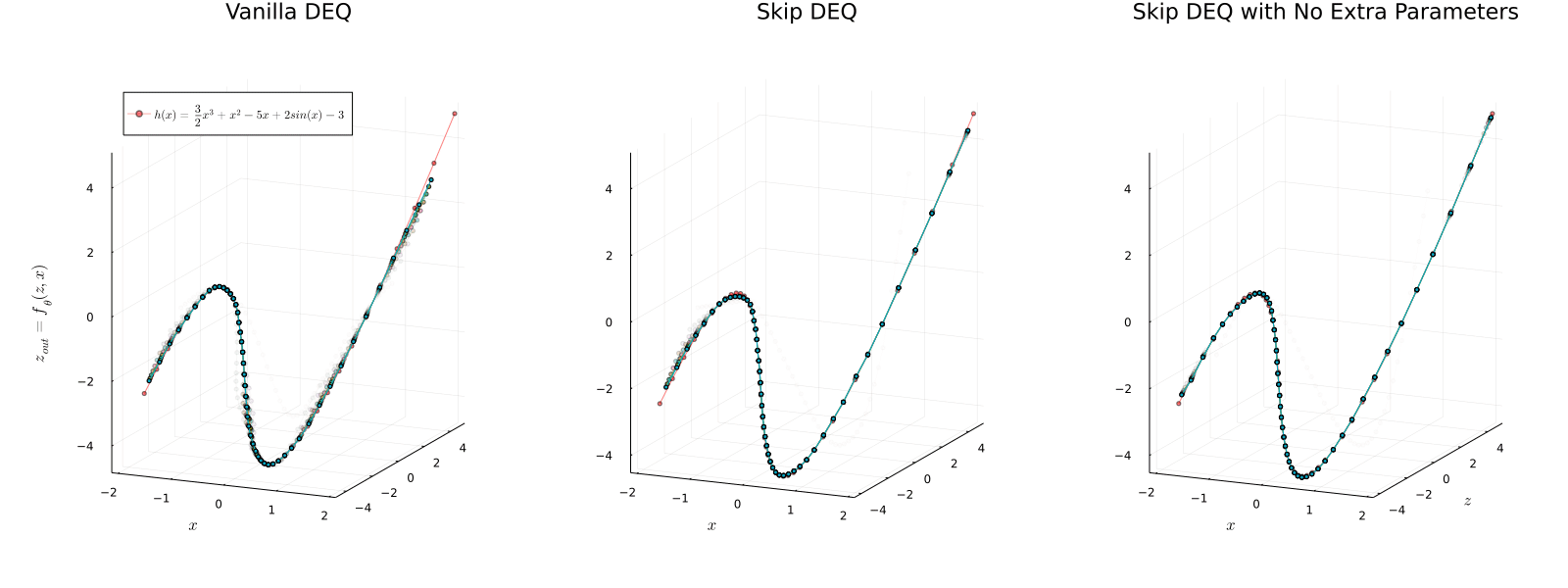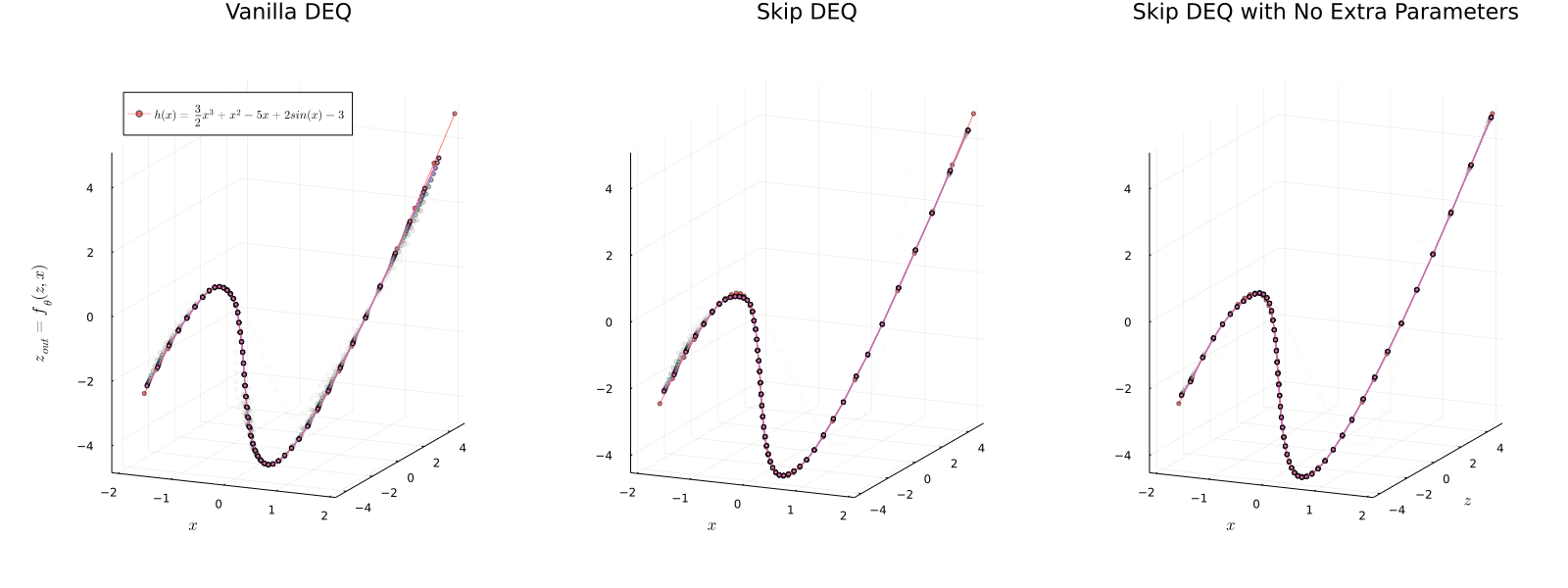
Implicit models separate the definition of a layer from the description of its solution process. While implicit layers allow features such as depth to adapt to new scenarios and inputs automatically, this adaptivity makes its computational expense challenging to predict. In this manuscript, we increase the "implicitness" of the DEQ by redefining the method in terms of an infinite time neural ODE, which paradoxically decreases the training cost over a standard neural ODE by 2-4x. Additionally, we address the question: is there a way to simultaneously achieve the robustness of implicit layers while allowing the reduced computational expense of an explicit layer? To solve this, we develop Skip and Skip Reg. DEQ, an implicit-explicit (IMEX) layer that simultaneously trains an explicit prediction followed by an implicit correction. We show that training this explicit predictor is free and even decreases the training time by 1.11-3.19x. Together, this manuscript shows how bridging the dichotomy of implicit and explicit deep learning can combine the advantages of both techniques.
PDF Abstract CIFAR-10
CIFAR-10
 ImageNet
ImageNet
