MixPHM: Redundancy-Aware Parameter-Efficient Tuning for Low-Resource Visual Question Answering
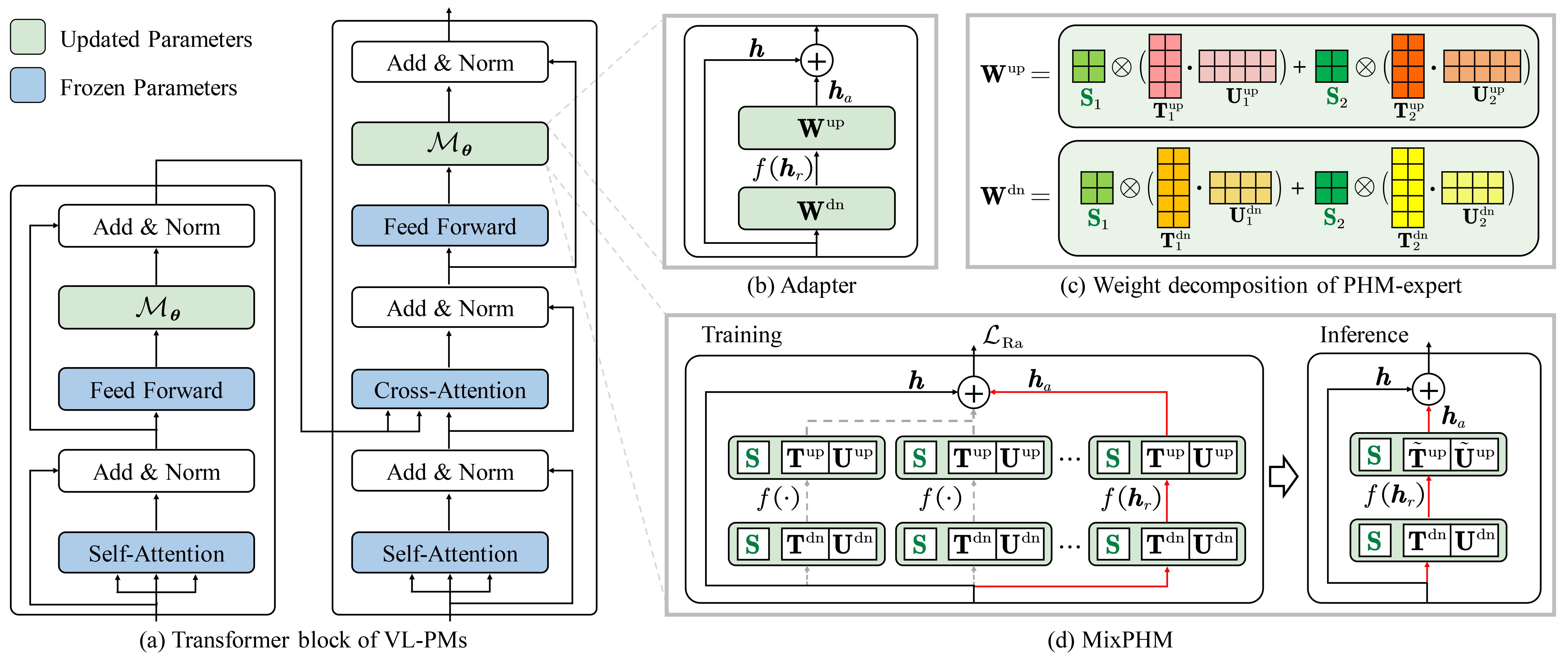
Recently, finetuning pretrained Vision-Language Models (VLMs) has been a prevailing paradigm for achieving state-of-the-art performance in Visual Question Answering (VQA). However, as VLMs scale, finetuning full model parameters for a given task in low-resource settings becomes computationally expensive, storage inefficient, and prone to overfitting. Current parameter-efficient tuning methods dramatically reduce the number of tunable parameters, but there still exists a significant performance gap with full finetuning. In this paper, we propose MixPHM, a redundancy-aware parameter-efficient tuning method that outperforms full finetuning in low-resource VQA. Specifically, MixPHM is a lightweight module implemented by multiple PHM-experts in a mixture-of-experts manner. To reduce parameter redundancy, MixPHM reparameterizes expert weights in a low-rank subspace and shares part of the weights inside and across experts. Moreover, based on a quantitative redundancy analysis for adapters, we propose Redundancy Regularization to reduce task-irrelevant redundancy while promoting task-relevant correlation in MixPHM representations. Experiments conducted on VQA v2, GQA, and OK-VQA demonstrate that MixPHM outperforms state-of-the-art parameter-efficient methods and is the only one consistently surpassing full finetuning.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract



 Visual Question Answering
Visual Question Answering
 GQA
GQA
 Visual Question Answering v2.0
Visual Question Answering v2.0
 OK-VQA
OK-VQA
