Model Accuracy and Runtime Tradeoff in Distributed Deep Learning:A Systematic Study
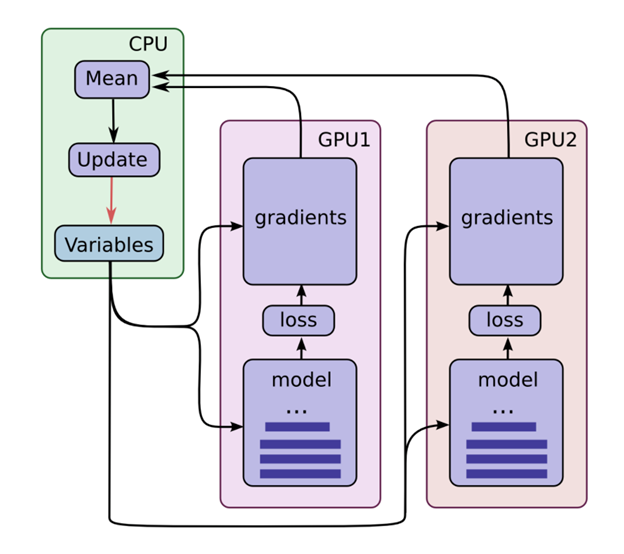
This paper presents Rudra, a parameter server based distributed computing framework tuned for training large-scale deep neural networks. Using variants of the asynchronous stochastic gradient descent algorithm we study the impact of synchronization protocol, stale gradient updates, minibatch size, learning rates, and number of learners on runtime performance and model accuracy. We introduce a new learning rate modulation strategy to counter the effect of stale gradients and propose a new synchronization protocol that can effectively bound the staleness in gradients, improve runtime performance and achieve good model accuracy. Our empirical investigation reveals a principled approach for distributed training of neural networks: the mini-batch size per learner should be reduced as more learners are added to the system to preserve the model accuracy. We validate this approach using commonly-used image classification benchmarks: CIFAR10 and ImageNet.
PDF Abstract


 CIFAR-10
CIFAR-10
