MSViT: Dynamic Mixed-Scale Tokenization for Vision Transformers
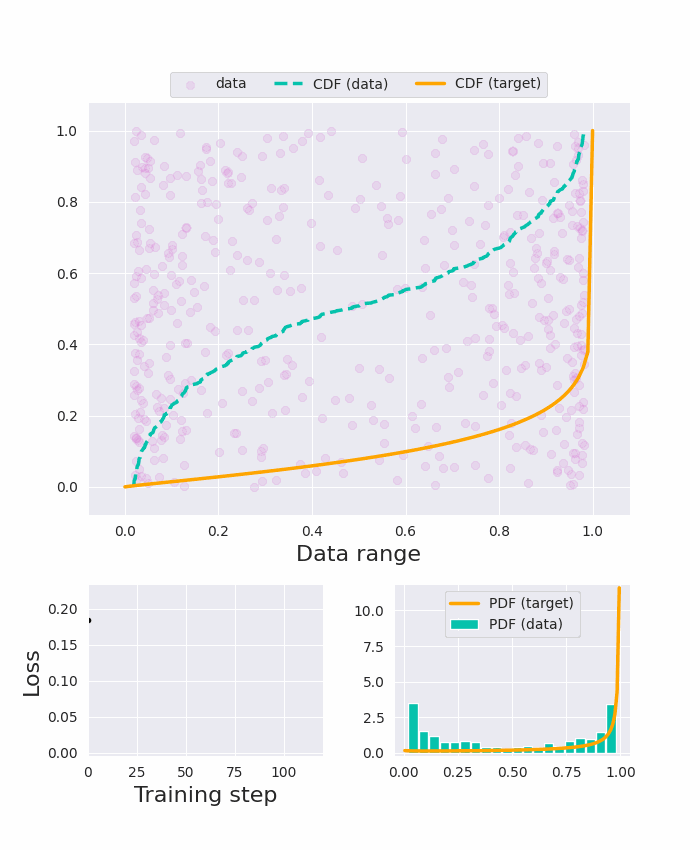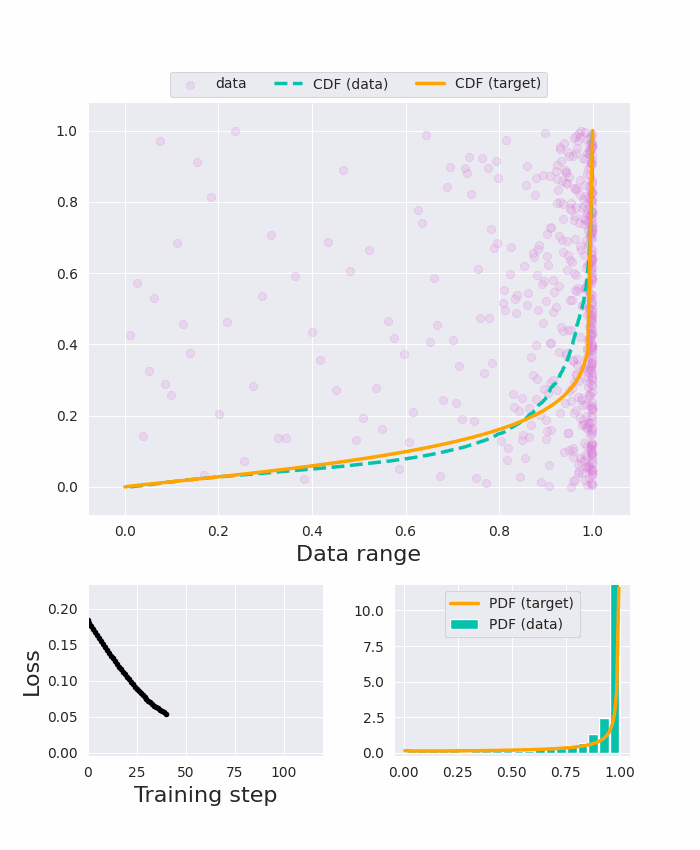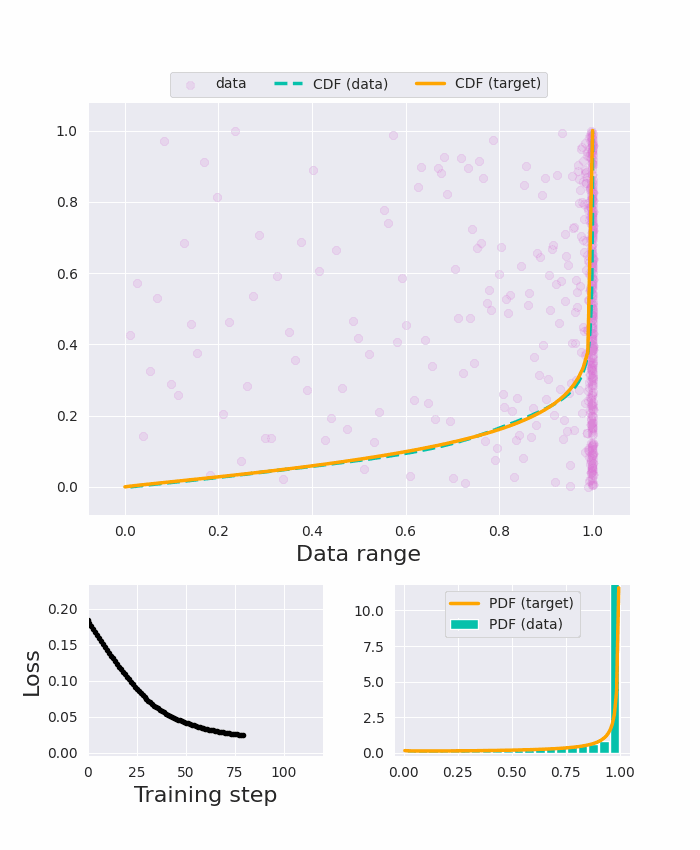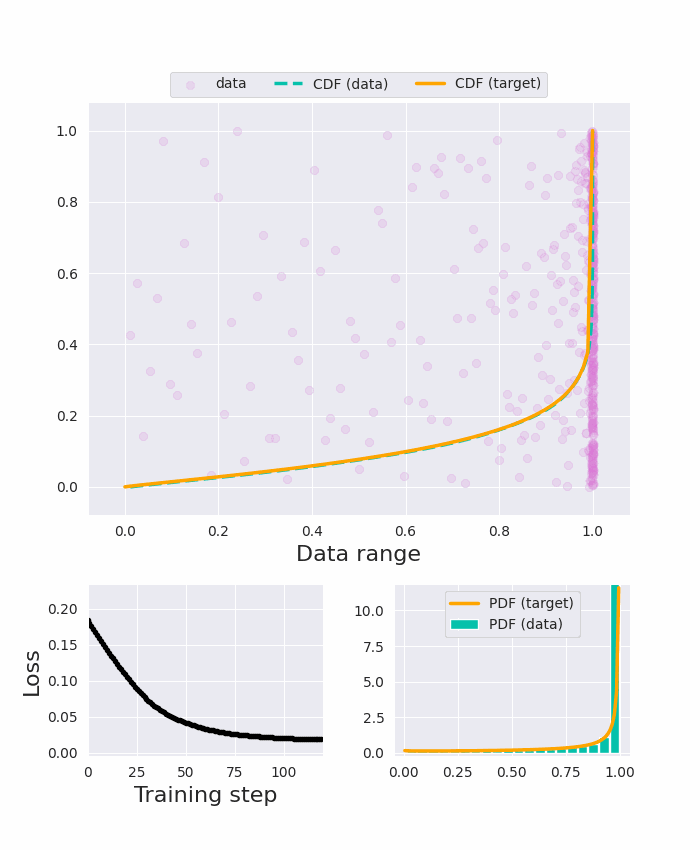
The input tokens to Vision Transformers carry little semantic meaning as they are defined as regular equal-sized patches of the input image, regardless of its content. However, processing uniform background areas of an image should not necessitate as much compute as dense, cluttered areas. To address this issue, we propose a dynamic mixed-scale tokenization scheme for ViT, MSViT. Our method introduces a conditional gating mechanism that selects the optimal token scale for every image region, such that the number of tokens is dynamically determined per input. In addition, to enhance the conditional behavior of the gate during training, we introduce a novel generalization of the batch-shaping loss. We show that our gating module is able to learn meaningful semantics despite operating locally at the coarse patch-level. The proposed gating module is lightweight, agnostic to the choice of transformer backbone, and trained within a few epochs with little training overhead. Furthermore, in contrast to token pruning, MSViT does not lose information about the input, thus can be readily applied for dense tasks. We validate MSViT on the tasks of classification and segmentation where it leads to improved accuracy-complexity trade-off.
PDF Abstract
 ADE20K
ADE20K
