MuGI: Enhancing Information Retrieval through Multi-Text Generation Integration with Large Language Models
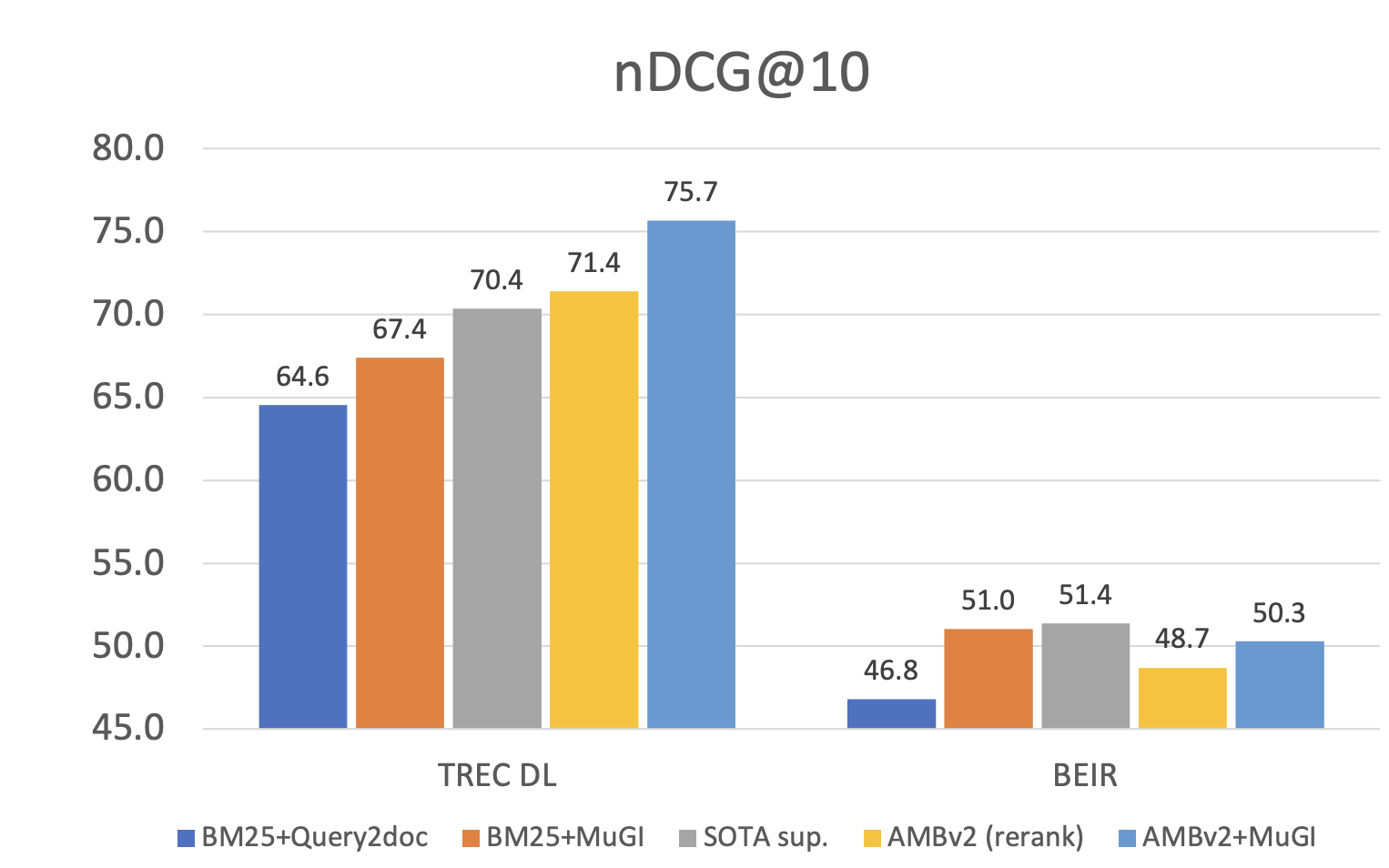
Large Language Models (LLMs) have emerged as a pivotal force in language technology. Their robust reasoning capabilities and expansive knowledge repositories have enabled exceptional zero-shot generalization abilities across various facets of the natural language processing field, including information retrieval (IR). In this paper, we conduct an in-depth investigation into the utility of documents generated by LLMs for IR. We introduce a simple yet effective framework, Multi-Text Generation Integration (MuGI), to augment existing IR methodologies. Specifically, we prompt LLMs to generate multiple pseudo references and integrate with query for retrieval. The training-free MuGI model eclipses existing query expansion strategies, setting a new standard in sparse retrieval. It outstrips supervised counterparts like ANCE and DPR, achieving a notable over 18% enhancement in BM25 on the TREC DL dataset and a 7.5% increase on BEIR. Through MuGI, we have forged a rapid and high-fidelity re-ranking pipeline. This allows a relatively small 110M parameter retriever to surpass the performance of larger 3B models in in-domain evaluations, while also bridging the gap in out-of-distribution situations. We release our code and all generated references at https://github.com/lezhang7/Retrieval_MuGI.
PDF Abstract



 BEIR
BEIR
