MuLan: Multimodal-LLM Agent for Progressive Multi-Object Diffusion
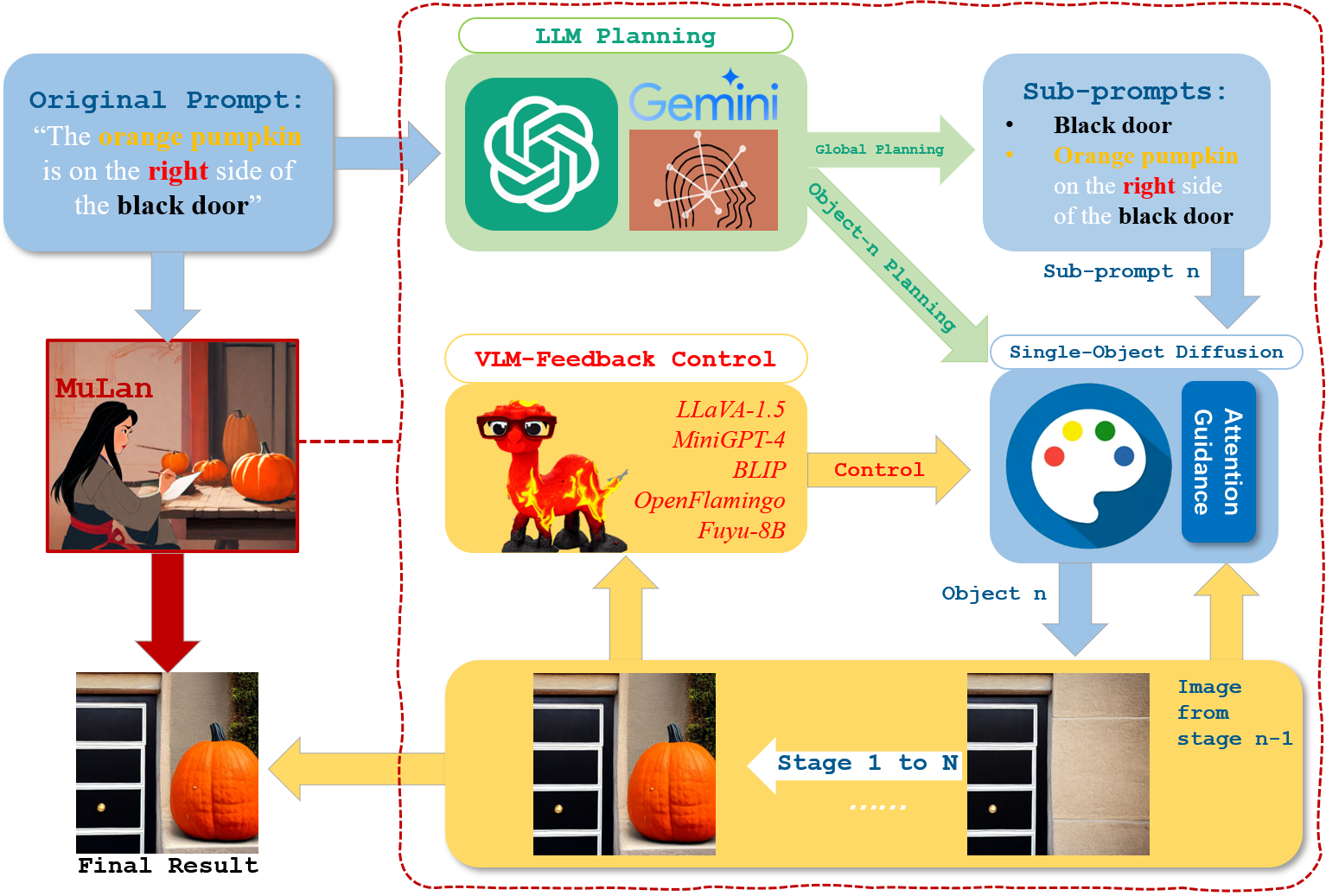
Existing text-to-image models still struggle to generate images of multiple objects, especially in handling their spatial positions, relative sizes, overlapping, and attribute bindings. In this paper, we develop a training-free Multimodal-LLM agent (MuLan) to address these challenges by progressive multi-object generation with planning and feedback control, like a human painter. MuLan harnesses a large language model (LLM) to decompose a prompt to a sequence of sub-tasks, each generating only one object conditioned on previously generated objects by stable diffusion. Unlike existing LLM-grounded methods, MuLan only produces a high-level plan at the beginning while the exact size and location of each object are determined by an LLM and attention guidance upon each sub-task. Moreover, MuLan adopts a vision-language model (VLM) to provide feedback to the image generated in each sub-task and control the diffusion model to re-generate the image if it violates the original prompt. Hence, each model in every step of MuLan only needs to address an easy sub-task it is specialized for. We collect 200 prompts containing multi-objects with spatial relationships and attribute bindings from different benchmarks to evaluate MuLan. The results demonstrate the superiority of MuLan in generating multiple objects over baselines. The code is available on https://github.com/measure-infinity/mulan-code.
PDF Abstract


