Multi-Domain Processing via Hybrid Denoising Networks for Speech Enhancement
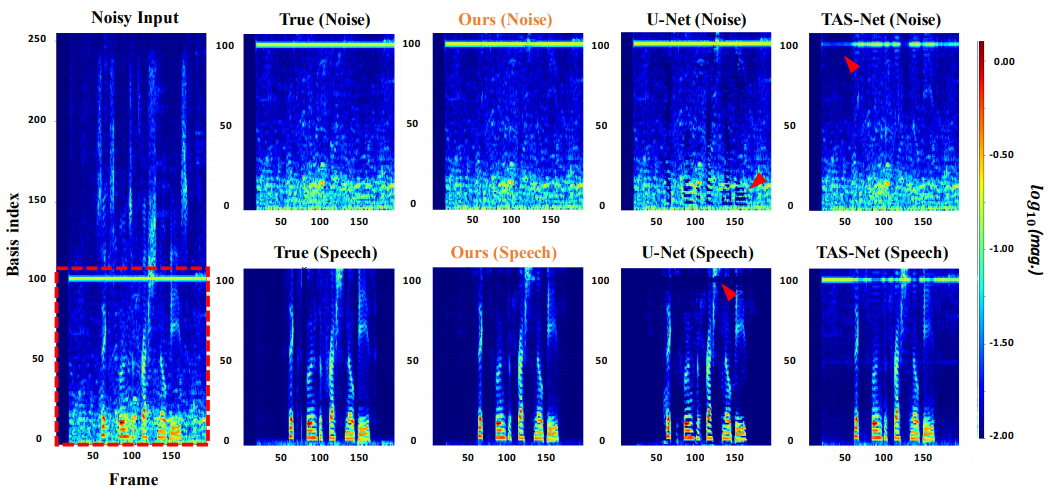
We present a hybrid framework that leverages the trade-off between temporal and frequency precision in audio representations to improve the performance of speech enhancement task. We first show that conventional approaches using specific representations such as raw-audio and spectrograms are each effective at targeting different types of noise. By integrating both approaches, our model can learn multi-scale and multi-domain features, effectively removing noise existing on different regions on the time-frequency space in a complementary way. Experimental results show that the proposed hybrid model yields better performance and robustness than using each model individually.
PDF Abstract
Tasks
Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
