Multiple Meta-model Quantifying for Medical Visual Question Answering
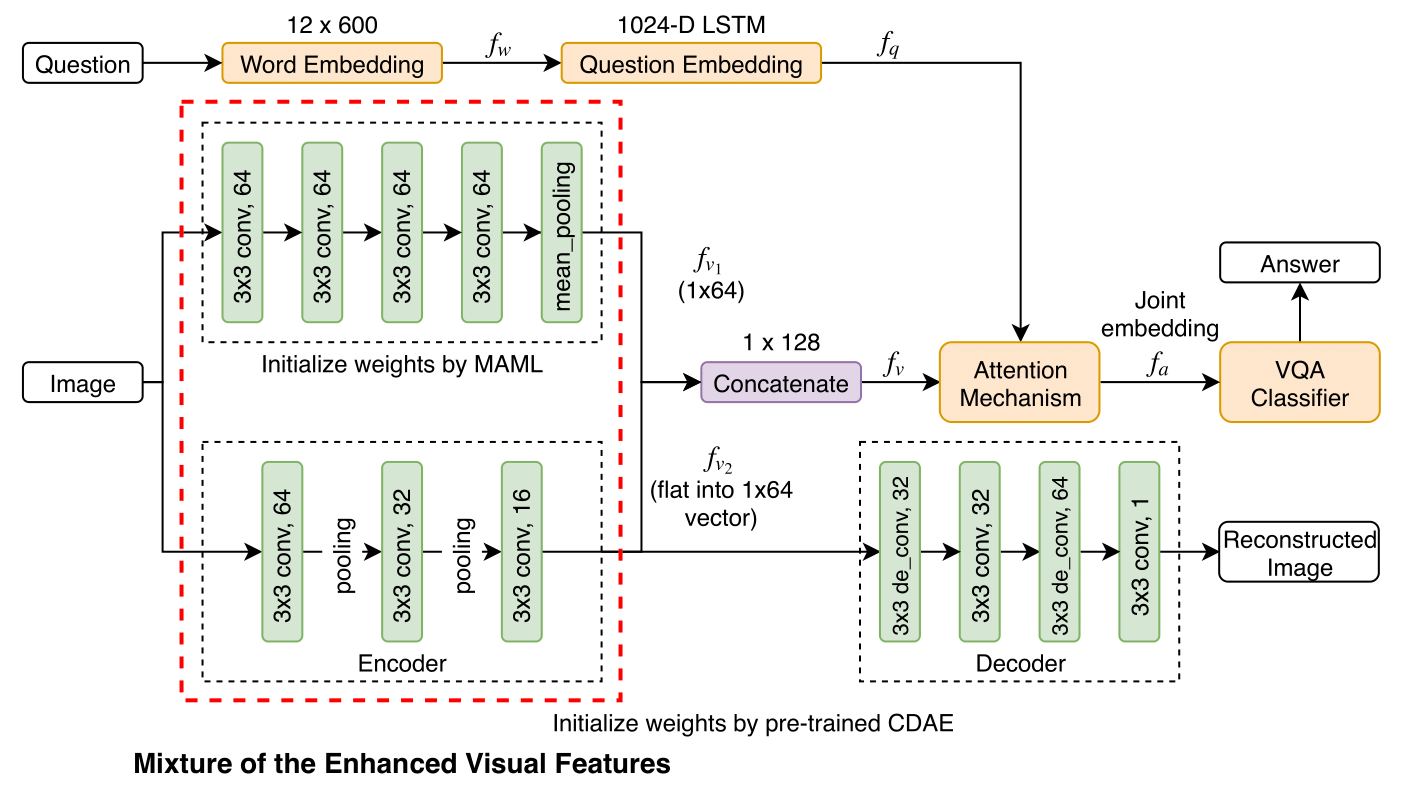
Transfer learning is an important step to extract meaningful features and overcome the data limitation in the medical Visual Question Answering (VQA) task. However, most of the existing medical VQA methods rely on external data for transfer learning, while the meta-data within the dataset is not fully utilized. In this paper, we present a new multiple meta-model quantifying method that effectively learns meta-annotation and leverages meaningful features to the medical VQA task. Our proposed method is designed to increase meta-data by auto-annotation, deal with noisy labels, and output meta-models which provide robust features for medical VQA tasks. Extensively experimental results on two public medical VQA datasets show that our approach achieves superior accuracy in comparison with other state-of-the-art methods, while does not require external data to train meta-models.
PDF Abstract





 VQA-RAD
VQA-RAD
 PathVQA
PathVQA

