NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
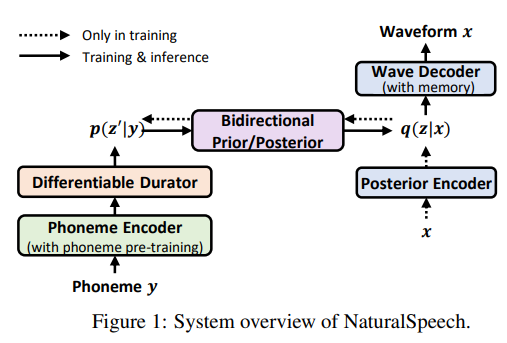
Text to speech (TTS) has made rapid progress in both academia and industry in recent years. Some questions naturally arise that whether a TTS system can achieve human-level quality, how to define/judge that quality and how to achieve it. In this paper, we answer these questions by first defining the human-level quality based on the statistical significance of subjective measure and introducing appropriate guidelines to judge it, and then developing a TTS system called NaturalSpeech that achieves human-level quality on a benchmark dataset. Specifically, we leverage a variational autoencoder (VAE) for end-to-end text to waveform generation, with several key modules to enhance the capacity of the prior from text and reduce the complexity of the posterior from speech, including phoneme pre-training, differentiable duration modeling, bidirectional prior/posterior modeling, and a memory mechanism in VAE. Experiment evaluations on popular LJSpeech dataset show that our proposed NaturalSpeech achieves -0.01 CMOS (comparative mean opinion score) to human recordings at the sentence level, with Wilcoxon signed rank test at p-level p >> 0.05, which demonstrates no statistically significant difference from human recordings for the first time on this dataset.
PDF AbstractCode



Datasets
 LJSpeech
LJSpeech
Results from the Paper
 Ranked #1 on
Text-To-Speech Synthesis
on LJSpeech
(using extra training data)
Ranked #1 on
Text-To-Speech Synthesis
on LJSpeech
(using extra training data)
