Neighboring Perturbations of Knowledge Editing on Large Language Models
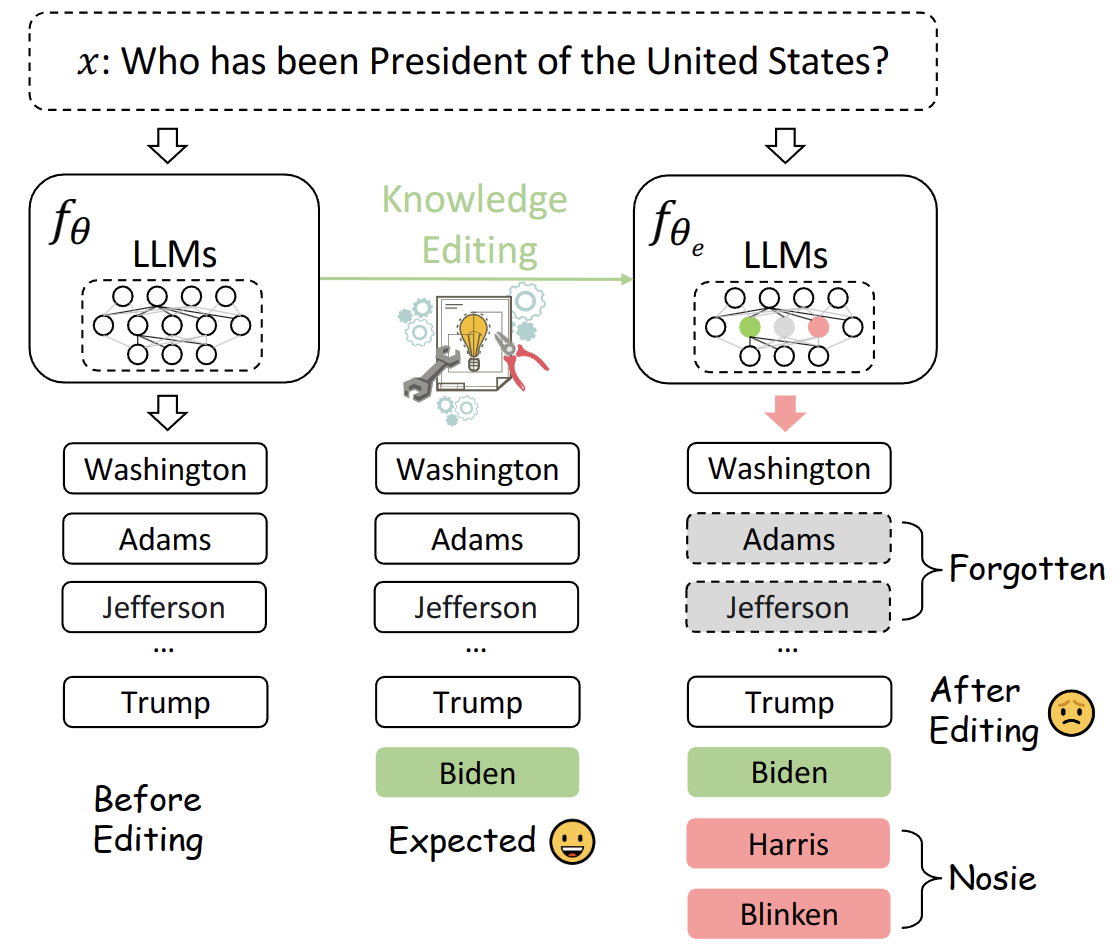
Despite their exceptional capabilities, large language models (LLMs) are prone to generating unintended text due to false or outdated knowledge. Given the resource-intensive nature of retraining LLMs, there has been a notable increase in the development of knowledge editing. However, current approaches and evaluations rarely explore the perturbation of editing on neighboring knowledge. This paper studies whether updating new knowledge to LLMs perturbs the neighboring knowledge encapsulated within them. Specifically, we seek to figure out whether appending a new answer into an answer list to a factual question leads to catastrophic forgetting of original correct answers in this list, as well as unintentional inclusion of incorrect answers. A metric of additivity is introduced and a benchmark dubbed as Perturbation Evaluation of Appending Knowledge (PEAK) is constructed to evaluate the degree of perturbation to neighboring knowledge when appending new knowledge. Besides, a plug-and-play framework termed Appending via Preservation and Prevention (APP) is proposed to mitigate the neighboring perturbation by maintaining the integrity of the answer list. Experiments demonstrate the effectiveness of APP coupling with four editing methods on three LLMs.
PDF Abstract

