Neural Dialogue State Tracking with Temporally Expressive Networks
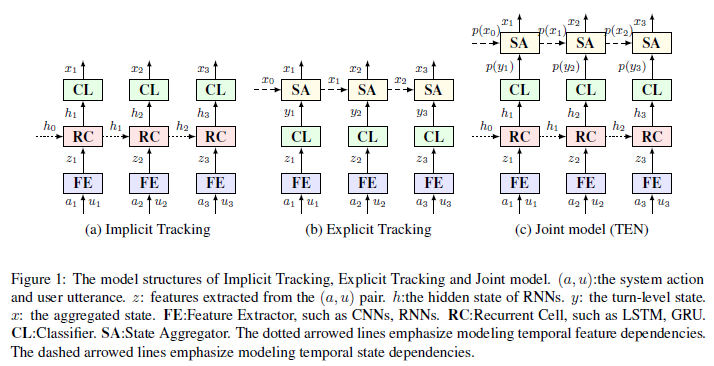
Dialogue state tracking (DST) is an important part of a spoken dialogue system. Existing DST models either ignore temporal feature dependencies across dialogue turns or fail to explicitly model temporal state dependencies in a dialogue. In this work, we propose Temporally Expressive Networks (TEN) to jointly model the two types of temporal dependencies in DST. The TEN model utilizes the power of recurrent networks and probabilistic graphical models. Evaluating on standard datasets, TEN is demonstrated to be effective in improving the accuracy of turn-level-state prediction and the state aggregation.
PDF Abstract Findings of 2020 PDF Findings of 2020 Abstract

Datasets
 MultiWOZ
MultiWOZ
 Wizard-of-Oz
Wizard-of-Oz
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
