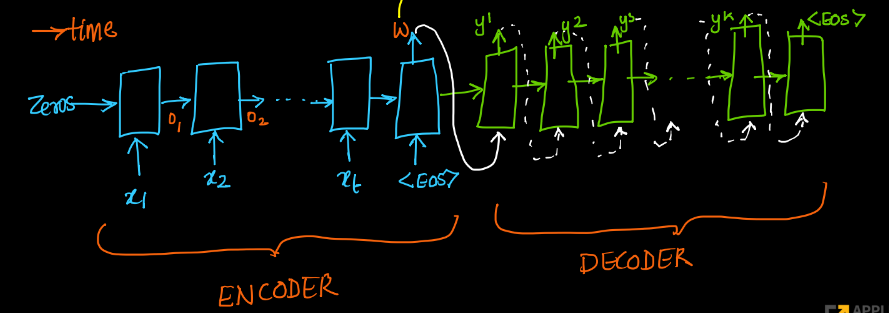
Neural Machine Translation for Low-Resourced Indian Languages
A large number of significant assets are available online in English, which is frequently translated into native languages to ease the information sharing among local people who are not much familiar with English. However, manual translation is a very tedious, costly, and time-taking process. To this end, machine translation is an effective approach to convert text to a different language without any human involvement. Neural machine translation (NMT) is one of the most proficient translation techniques amongst all existing machine translation systems. In this paper, we have applied NMT on two of the most morphological rich Indian languages, i.e. English-Tamil and English-Malayalam. We proposed a novel NMT model using Multihead self-attention along with pre-trained Byte-Pair-Encoded (BPE) and MultiBPE embeddings to develop an efficient translation system that overcomes the OOV (Out Of Vocabulary) problem for low resourced morphological rich Indian languages which do not have much translation available online. We also collected corpus from different sources, addressed the issues with these publicly available data and refined them for further uses. We used the BLEU score for evaluating our system performance. Experimental results and survey confirmed that our proposed translator (24.34 and 9.78 BLEU score) outperforms Google translator (9.40 and 5.94 BLEU score) respectively.
PDF Abstract LREC 2020 PDF LREC 2020 Abstract


