NExT-Chat: An LMM for Chat, Detection and Segmentation
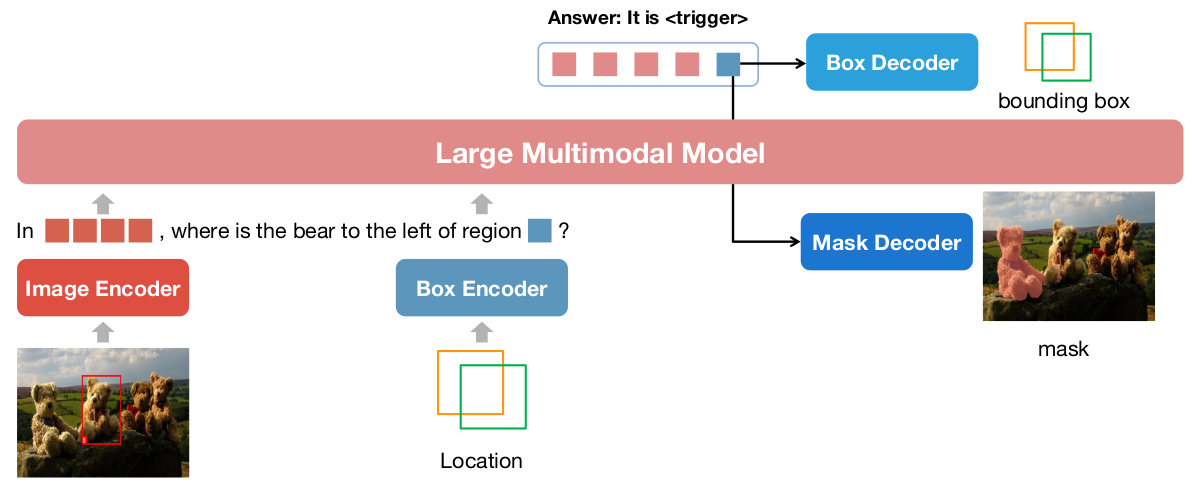
The development of large language models (LLMs) has greatly advanced the field of multimodal understanding, leading to the emergence of large multimodal models (LMMs). In order to enhance the level of visual comprehension, recent studies have equipped LMMs with region-level understanding capabilities by representing object bounding box coordinates as a series of text sequences (pix2seq). In this paper, we introduce a novel paradigm for object location modeling called pix2emb method, where we ask the LMM to output the location embeddings and then decode them with different decoders. This paradigm allows us to use different location formats (such as bounding boxes and masks) in multimodal conversations. Leveraging the proposed pix2emb method, we train an LMM named NExT-Chat and demonstrate its capability of handling multiple tasks like visual grounding, region captioning, and grounded reasoning. Comprehensive experiments show the effectiveness of our NExT-Chat on various tasks, e.g., NExT-Chat (87.7) vs. Shikra (86.9) on POPE-Random, NExT-Chat (68.9) vs. LISA (67.9) on referring expression segmentation task, and NExT-Chat (79.6) vs. Kosmos-2 (62.3) on region caption task. The code and model are released at https://github.com/NExT-ChatV/NExT-Chat.
PDF Abstract



 VCR
VCR
 Flickr30K Entities
Flickr30K Entities
