Nonparametric Feature Impact and Importance
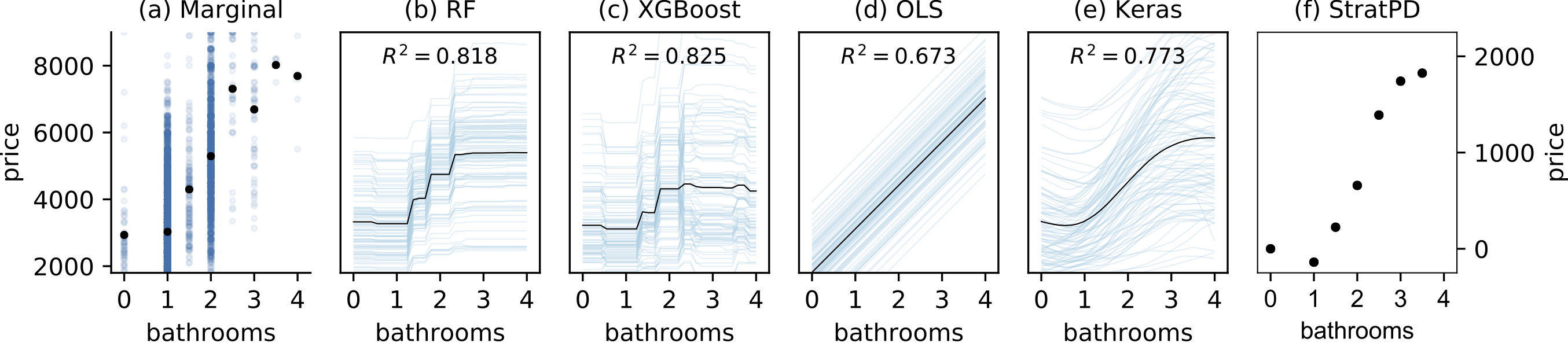
Practitioners use feature importance to rank and eliminate weak predictors during model development in an effort to simplify models and improve generality. Unfortunately, they also routinely conflate such feature importance measures with feature impact, the isolated effect of an explanatory variable on the response variable. This can lead to real-world consequences when importance is inappropriately interpreted as impact for business or medical insight purposes. The dominant approach for computing importances is through interrogation of a fitted model, which works well for feature selection, but gives distorted measures of feature impact. The same method applied to the same data set can yield different feature importances, depending on the model, leading us to conclude that impact should be computed directly from the data. While there are nonparametric feature selection algorithms, they typically provide feature rankings, rather than measures of impact or importance. They also typically focus on single-variable associations with the response. In this paper, we give mathematical definitions of feature impact and importance, derived from partial dependence curves, that operate directly on the data. To assess quality, we show that features ranked by these definitions are competitive with existing feature selection techniques using three real data sets for predictive tasks.
PDF Abstract

