On the use of Silver Standard Data for Zero-shot Classification Tasks in Information Extraction
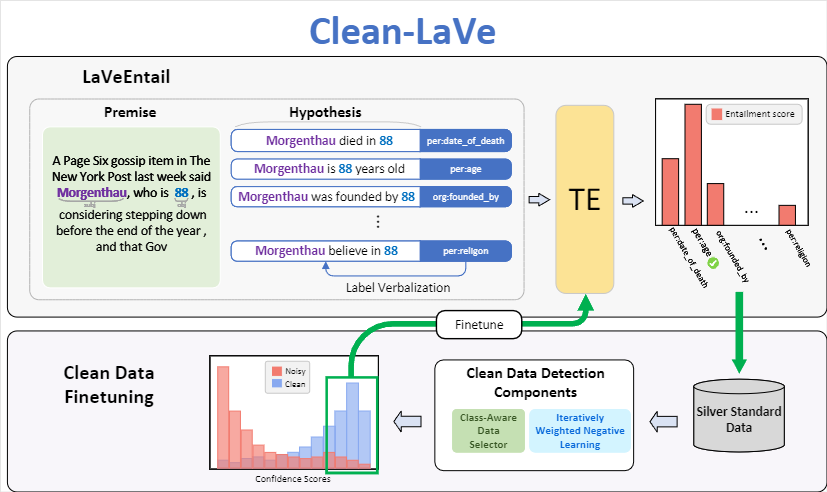
The superior performance of supervised classification methods in the information extraction (IE) area heavily relies on a large amount of gold standard data. Recent zero-shot classification methods converted the task to other NLP tasks (e.g., textual entailment) and used off-the-shelf models of these NLP tasks to directly perform inference on the test data without using a large amount of IE annotation data. A potentially valuable by-product of these methods is the large-scale silver standard data, i.e., pseudo-labeled data by the off-the-shelf models of other NLP tasks. However, there is no further investigation into the use of these data. In this paper, we propose a new framework, Clean-LaVe, which aims to utilize silver standard data to enhance the zero-shot performance. Clean-LaVe includes four phases: (1) Obtaining silver data; (2) Identifying relatively clean data from silver data; (3) Finetuning the off-the-shelf model using clean data; (4) Inference on the test data. The experimental results show that Clean-LaVe can outperform the baseline by 5% and 6% on TACRED and Wiki80 dataset in the zero-shot relation classification task, and by 3%-7% on Smile (Korean and Polish) in the zero-shot cross-lingual relation classification task, and by 8% on ACE05-E+ in the zero-shot event argument classification task. The code is share in https://github.com/wjw136/Clean_LaVe.git.
PDF Abstract




