Peering Through Preferences: Unraveling Feedback Acquisition for Aligning Large Language Models
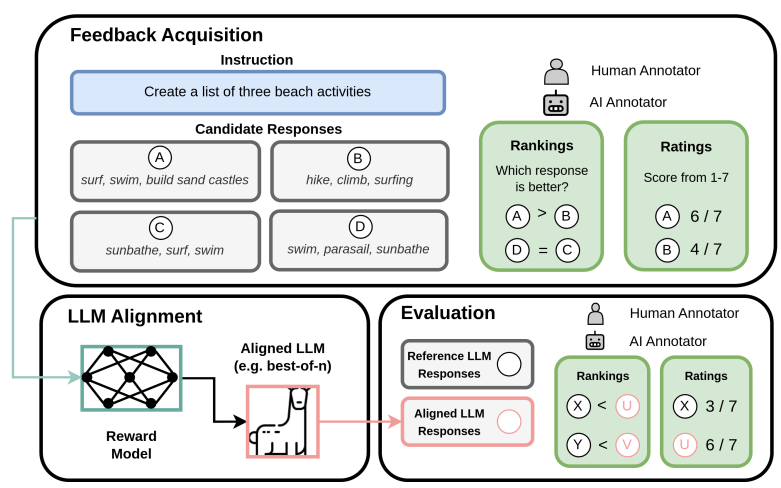
Aligning large language models (LLMs) with human values and intents critically involves the use of human or AI feedback. While dense feedback annotations are expensive to acquire and integrate, sparse feedback presents a structural design choice between ratings (e.g., score Response A on a scale of 1-7) and rankings (e.g., is Response A better than Response B?). In this work, we analyze the effect of this design choice for the alignment and evaluation of LLMs. We uncover an inconsistency problem wherein the preferences inferred from ratings and rankings significantly disagree 60% for both human and AI annotators. Our subsequent analysis identifies various facets of annotator biases that explain this phenomena, such as human annotators would rate denser responses higher while preferring accuracy during pairwise judgments. To our surprise, we also observe that the choice of feedback protocol also has a significant effect on the evaluation of aligned LLMs. In particular, we find that LLMs that leverage rankings data for alignment (say model X) are preferred over those that leverage ratings data (say model Y), with a rank-based evaluation protocol (is X/Y's response better than reference response?) but not with a rating-based evaluation protocol (score Rank X/Y's response on a scale of 1-7). Our findings thus shed light on critical gaps in methods for evaluating the real-world utility of language models and their strong dependence on the feedback protocol used for alignment. Our code and data are available at https://github.com/Hritikbansal/sparse_feedback.
PDF Abstract
